第九章番外-数据驱动安全
什么是数据驱动安全
2013年RSA信息安全大会的主题是“Mastering data. Securing the world”(掌控数据,保护世界),自此数据分析开始被信息安全工业界所重视。事实上,在此之前,入侵检测领域已经在学术界和工业界产品中使用数据分析技术在解决网络安全问题。正如在第九章 入侵检测中所述,入侵检测技术中所使用的基于异常的检测本质上就是数据分析技术。 相比较于入侵检测技术主要关注的入侵风险,数据分析技术关注的焦点问题涵盖了信息安全领域的方方面面,包括:拒绝服务攻击检测、欺诈检测、钓鱼攻击检测、服务滥用和搭便车行为检测等等。 卡佩利指出,技术需求如今仍然非常强劲。他在接受信息安全媒体集团采访时表示,Gartner估计2016年市场规模,全球将大数据和机器学习应用到安全用例的花费近8亿美元(约55亿人民币),大数据占比约80%,机器学习20%。 企业正将这些技术视为一个架构的两大组成部门。典型的用例是部署大数据日志管理平台,然后在平台上部署某类机器学习能力,以自动发现数据中的隐藏模式,例如未授权访问。 又比如,许多大数据客户使用大数据技术获取应用程序日志,然后利用机器学习发现异常行为。 卡佩利预测,对许多组织机构而言,大数据和机器学习这两大技术均能作为强大的网络安全工具,未来将必不可少。卡佩利还讨论了大数据和机器学习从广泛的IT应用演进到特定的安全功能、这些技术的新兴用例、以及部署这些技术的先决条件。
数据驱动安全的现有代表作
近年,越来越多的企业开始利用数据驱动的人工智能技术对抗网络黑产,百度安全利用机器学习进行非法网页检测;阿里巴巴基于云上实时计算平台和机器学习能力, 对于网站攻击进行防御等;腾讯优图DeepEye智能鉴黄技术,可对目标图片进行系统识别,承载着每日数亿张的图片识别,大幅度降低企业因色情违规收到通报的次数,准确率高达99.9%。 蚂蚁金服在其生态体系中的诸多业务中应用了大数据技术。蚂蚁金服主导的网商银行,及其前身“阿里小贷”,多年来通过大数据模型来发放贷款。蚂蚁金服通过对客户相关数据的分析,依照相关的模型,综合判断风险,形成了网络贷款的“310”模式,即:“3分钟申请、1秒钟到账、0人工干预”的服务标准。5年多来,为400多万小微企业提供了累计超过7000亿的贷款,帮助了他们解决了资金难题,促进了这些小微企业生存和发展,并创造了更多的就业机会。 类似地,大数据的应用也充分得体现在蚂蚁金服生态中的第三方征信公司芝麻信用。“芝麻信用分”是芝麻信用对海量信息数据的综合处理和评估,主要包含了用户信用历史、行为偏好、履约能力、身份特质、人脉关系五个维度。芝麻信用基于阿里巴巴的电商交易数据和蚂蚁金服的互联网金融数据,并与公安网等公共机构以及合作伙伴建立数据合作,与传统征信数据不同,芝麻信用数据涵盖了信用卡还款、网购、转账、理财、水电煤缴费、租房信息、住址搬迁历史、社交关系等等。 “芝麻信用”通过分析大量的网络交易及行为数据,可对用户进行信用评估,这些信用评估可以帮助互联网金融企业对用户的还款意愿及还款能力得出结论,继而为用户提供快速授信及现金分期服务。 创立于2004年12月的支付宝通过多年的探索,已经实现了风险控制的智能化,防控效果显著。 支付宝风控系统利用原来的历史交易数据进行个性化的验证,提高账户安全性。80%左右的风险事件在智能风控环节就能解决。除了事后审核,事前预防、事中监控也非常重要——事前,将账户的风险分级,不同账户对应不同风险等级;事中,对新上线的产品进行风险评审以及监控策略方案评审。
附录A:RSA 2013信息安全大会上的数据分析相关议题
- Data-Driven Security - Where's the Data?
- Big Data Transforms Security
- GOOD GUYS VS BAD GUYS: USING BIG DATA TO COUNTERACT ADVANCED THREATS
- BIG DATA FOR SECURITY: HOW CAN I PUT BIG DATA TO WORK FOR ME?
参考资料
为什么需要数据驱动安全
企业的计算机网络系统产生大量日志数据,大数据可以针对所有的系统运行记录进行分析,可以弥补时间点检测技术的不足,发现网络攻击的蛛丝马迹。在这个基础上,结合传统的检测技术,可以组成基于记忆的检测系统,这是由国内安全厂商启明星辰提出的思路。 应用大数据分析,需要强大的数据采集平台,以及强大的数据分析处理能力。最理想的情况是建立全球化的数据分析引擎,在全球范围内进行相关数据的关联性分析。这样就能克服信息分布孤岛带来的调查取证难的问题,更容易发现攻击。针对具体的网络、系统和应用的运行数据采集分析,捕获、挖掘、修复漏洞;对全球已经发生以及正在发生的网络攻击行为进行记录,并将这些海量的数据经过多维度的整合分析,自动生成漏洞库、黑客行为特征等数据库。对于具体的网络系统,全球化的安全监测,运用大数据技术,可以提前发现攻击,提前阻止攻击,减少攻击带来的经济损失。 对于大数据的定义,简单来讲就是,无法在一定时间内用常规软件工具对其内容进行存储、管理和处理的数据集合。它主要有5个维度特征,即5个“V”:Volume(容量),Variety(多样性),Velocity(速度),Veracity(准确性)和Value(价值)。我们把这5个V放到数据驱动安全的对抗技术研究的背景下,会发现新兴网络威胁和对网络空间安全防御的挑战也同时具备这5个特征:
Volume
计算机通信网络技术在最近几年的快速发展,特别是各国、各个城市、各个企业、各个家庭的互联网带宽都在逐年翻番。跨国、城际互联和IDC的网络带宽早以Gbps,甚至是10Gbps为单位衡量。家庭宽带网络接入和4G移动通信的100Mbps时代带来,使得单位时间内需要处理和分析的数据包数量呈现爆炸式几何级数增长。与此同时,信息化趋势借助互联网在世界各国都进入到了一个新的阶段。在我国,李克强总理在2015年的十二届全国人大三次会议提出的“互联网+”行动计划,推动移动互联网、云计算、大数据、物联网等与现代制造业结合,促进电子商务、工业互联网和互联网金融健康发展,引导互联网企业拓展国际市场,这会进一步推动网络传输和本地存储、处理的数据量规模快速膨胀。即使是传统的基于单个数据报文和网络会话级别数据流的安全检测机制面对这种规模的网络数据都有力不从心之感,在这样的海量数据级别进行入侵检测是真正的大海捞针。 根据思科2017年6月更新的流量统计报告《The Zettabyte Era: Trends and Analysis》:
- 全球IP流量在2021年将达到3.3 ZB,平均月度流量将达到278 EB(1 ZB = 1024 EB = 1024 * 1024 PB = 1024 * 1024 * 1024 TB)。
- 根据Arbor网络第12次年度基础设施安全报告,2014,2015和2016年,全球DDoS攻击的流量峰值分别达到了400,500和800Gbps;平均一次DDoS攻击的流量已经稳步达到1.2Gbps;一次DDoS攻击流量可以占去一个国家总流量的18%! 与此同时,攻击者为了完成一次网络攻击,同样需要收集和处理关于被攻击目标的海量情报数据。从这个角度来说,攻防双方谁能处理更多的数据,谁就能在网络空间安全对抗中获得更多的信息。
Variety
信息技术本身就呈现着多样化发展的特点,操作系统、应用软件、通信协议等软件技术百家齐放,PC、手机、平板、嵌入式设备等硬件产品快速更新换代,万物互联时代的APT攻击已经不再局限于针对PC、服务器的入侵和控制,任何可以联网、任何可以处理数据的设备与系统都是潜在的攻击目标。例如,对于入侵检测来说,仅仅一个基本的终端安全防护的任务就将面临终端设备多样性的挑战。同时,已有的通信协议多样化、加密等问题,一直以来都是网络流量识别与分类技术研究领域的难题。流量识别技术是网络入侵检测与保护的共性基础技术,无法准确分类流量就意味着无法准确识别出网络流量中夹杂的恶意代码、攻击负载和泄密数据。 根据Imperva Incapsula公司的2015年和2016年爬虫流量年度报告(统计数据采集自Incapsula网络中100万随机选取域名的167亿次页面访问),Web访问流量中的恶意爬虫在2015年的流量占比大约是29%,Web访问流量中的恶意爬虫在2016年的流量占比大约是28.9% 。从2012年到2016年的这5年流量分类占比统计数据和趋势来看,真人用户产生的流量行为在Web流量中的占比并不是压倒性优势。同时,爬虫(机器人)流量占比一直居高不下,恶意爬虫的流量占比甚至超过正常爬虫流量。  新技术的应用,新应用的产生,新威胁的出现都意味着会不断产生新类型的数据,数据的多样性既是数据分析的机遇,更是数据分析的挑战。
新技术的应用,新应用的产生,新威胁的出现都意味着会不断产生新类型的数据,数据的多样性既是数据分析的机遇,更是数据分析的挑战。
Velocity
Verizon发布的《2013年数据泄漏调查报告》已经揭示了数据窃密行为一旦发生,攻击者完全有可能在数小时,甚至是分钟、秒级别达成机密数据的窃取目的。泄密行为一旦产生,和系统被攻陷后通过应急响应可以夺回系统控制权不同,数据失窃应急控制措施只能终止未泄密数据的非法访问,对已泄密数据已经无力挽回。以APT攻击为例,APT攻击虽然普遍潜伏周期长,但留给APT防御一方的检测时间往往也是仅限于数据回传期间,而这个回传的持续时间窗口往往并不长。所以,APT防御者尽早发现入侵、尽早检测到APT攻击驻留行为,在数据回传行为还没开始之前及时处置掉所有驻留的恶意代码至关重要。 攻击者的终极目标是希望越早结束攻击对自己越有利,时间拖得越长其实也是增加了自己暴露和被发现的风险。以漏洞生命周期为例,攻击者在发掘出新漏洞之后,希望抢在软硬件厂商修补漏洞之前利用该未知漏洞攻击尽可能多的系统。厂商即使开发出漏洞补丁,但只要在终端用户没有安装补丁之前,攻击者依然有时间去利用漏洞攻击用户。从漏洞攻防过程来看,攻防双方争夺的目标就是漏洞暴漏于未修补状态的时间长短:谁先掌握未知漏洞信息,谁就在这场漏洞攻防战之中处于优势地位。 从这个角度来说,网络与系统攻防双方都希望提高自己的数据处理效率,缩短信息提取周期,更快的为自己下一步行动得出决策意见,抢先对手行动。
Veracity
网络和系统攻击行为不论是借助于社会工程学手段还是0day漏洞利用,一定会在网络流量或被攻击系统里留下蛛丝马迹。由于攻防双方的信息不对称问题,特别是攻防双方由于守方在明,攻方在暗,攻方可以通过大量的信息收集和交换行为获得关于守方的更准确信息。而守方对攻方信息的收集不仅缺少准确性,甚至大部分时间里对攻方信息一无所知。无论是网络入侵检测、主机入侵检测还是数据泄漏检测的系统构建者,误用检测和异常检测是最基本的安全检测理论基础。其中误用检测的基本原理是对已知攻击行为特征和模式的总结、建模,很显然这个检测理论在面对日益增长的网络攻击行为数量和类型是非常被动的。攻击者通过长时间的信息收集工作,可以设计出针对性的误用检测模型绕过技术来悄无声息的进出于目标网络和系统。即使是基于异常检测模型,无论是基于模式的异常检测,还是基于行为的异常检测,攻击者同样可以通过大量信息收集工作,推断出关于异常检测系统对“正常”模式和行为的判定标准和算法,进而可以针对性的伪装成正常业务和行为模式,躲避异常检测。 对于攻击者来说,在情报不足或掌握的是错误情报信息的情况下展开的攻击行为会极大的提升被发现风险。所有已公开的网络防御成功事件有一个共性特征:攻击者落入了防御者精心设计的检测陷进(典型的如DNSSinkholing技术、沙盒检测技术等)。 从这个角度来说,安全攻防双方一方面都希望获得关于对方的正确数据,同时,希望对方从自己这里获得的数据都是错误的。基于错误的数据,是无法得到一个有效的行动决策的。 另外,根据《思科2017年年度网络安全报告》中的说明,在联网型第三方云应用相关的 5000 个用户 活动中,仅有 1 个活动(占 0.02%)是可疑的(如下图所示):  因此,在海量正常用户行为数据中找到“稀少”的攻击行为要解决好“虚警率”高的问题。由于用户行为数据基数大,即使是百分之一的“虚警”也是十分可观的数据规模。“狼来了”的故事告诉我们:误报太多,一方面会造成用户的安全警惕性下降,在真正的威胁到来时失去及时响应能力。另一方面也会对用户的正常业务造成过多打扰,增加日常运营负担。
因此,在海量正常用户行为数据中找到“稀少”的攻击行为要解决好“虚警率”高的问题。由于用户行为数据基数大,即使是百分之一的“虚警”也是十分可观的数据规模。“狼来了”的故事告诉我们:误报太多,一方面会造成用户的安全警惕性下降,在真正的威胁到来时失去及时响应能力。另一方面也会对用户的正常业务造成过多打扰,增加日常运营负担。
Value
信息化带来的一个重要长期成果和不断累积价值就是大数据。安全虽然不“创造”价值,但“守护”价值。汽车跑的快靠油门,汽车卖得好靠刹车。一方面,所有人都享受和体验到了信息化、互联互通带来的良好用户体验,同时,随着越来越多的重大信息安全事件曝光在公众视野之中,消费者对产品和服务供给中信息安全的理解和要求也在不断提高,这必将迫使相关行业和产业链的参与者不得不投入更多资源在信息安全建设上。 APT攻击者的普遍动机就是为了窃取高价值数据,与此同时,对于很多被攻击对象来说,他们自己甚至都不如攻击者清楚自己企业中哪些信息资产是有高价值的。由于被攻击者自身对数据价值的认识不足,导致很多APT攻击事件中攻击者轻易的就访问到了这些高价值数据,根本就没有遇到任何有效的防御机制。换句话来说,如果企业能提前认识到自己的这些高价值数据,就有机会抢在攻击者发起APT攻击之前对这些数据进行更为有效的保护。 2015年开始兴起的勒索软件攻击件正成为一个日益严重的问题。企业通常认为支付赎金是取回数据最划算的办法,现实情况也可能正是这样。但是,我们所面临的问题是,每一个企业为了取回其文件而支付的赎金,会直接用于下一代勒索软件的开发。因此,我们看到勒索软件正以惊人的速度不断发展。勒索能够得逞的前提正是被加密数据本身的价值远远高于勒索赎金,从这个角度来看,网络空间数据的价值是真实存在且不断增加的。 通过以上的网络空间安全大数据特征分析我们可以得到3个重要结论:
- 网络空间安全攻防的研究对象都具备了大数据的5个典型特征。
- 网络空间安全攻防双方都已在自觉或不自觉的运用大数据理论和技术。
- 网络空间安全攻防成败的核心就是大数据能力的全面对抗。
数据驱动安全怎么做
数据驱动安全历史
依赖数据,使用数据分析和处理技术来解决网络安全问题到目前(2017年)为止大致经历了3个阶段: 第一个阶段的主要应用领域是入侵检测。具体来说,按照数据来源的差异,入侵检测技术又被分为基于主机的入侵检测和基于网络的入侵检测。按照数据分析的方法差异,可以分为基于误用(特征)的检测和基于异常的检测。数据挖掘、机器学习开始被安全研究人员引入到检测和对抗网络与系统入侵,不管是数据挖掘还是机器学习,本质上都是在建立一个分类器模型,把输入的数据识别为不同的分类结果输出,100%分类正确的分类器是不存在的。基于这个基本认知,100%的检测和防护能力也是无法实现的,因此,为了提高整个网络与系统的安全性,纵深防御理念逐渐成为了网络空间安全研究的一个共识:通过增加多种异构的“安全分类器”,以图实现更高的分类准确性,进而逼近100%的检测和防护准确率。这个阶段的数据分析方法主要缺陷在于没有有效的整合不同数据源产生的数据、信息、日志和报警等,局部的安全设备、网络设备和服务系统产生的日志和报警没有被放在全局视角进行深度关联分析,SIEM (Security Information and Event Management)就是在这样的背景下应运而生。 第二个阶段的代表性产品形态是SIEM。把安全信息和事件统一管理起来的第一步就是把不同入侵检测系统和产品的报警信息统一收集和集中关联分析,挖掘出具备可行动能力的信息提供给安全专家,辅助运维和管理人员采取及时有效的安全响应措施,应对更为复杂的网络安全态势变化。然后随着需要收集的数据规模越来越大,需要处理和分析的数据种类越来越多,SIEM底层的数据能力和计算能力需要更上一层楼,这个时候,大数据分析能力就呼之欲出了。 第三个阶段就是现在,应用领域非常广泛,包括入侵检测、漏洞挖掘与分析、欺诈检测、钓鱼攻击检测、SPAM检测等等。主要依赖的就是大数据分析能力,具体来说包括云计算、数据分析、数据挖掘、机器学习和人工智能等。由于底层数据能力和计算能力的质变提升,现在的数据驱动安全产品除了像SIEM一样对报警信息和日志进行关联分析,还可以对包括源代码、二进制文件、音视频和图像等海量非结构化数据进行分析,关联分析的数据时间跨度也不再局限于小时、天级别,以月度、甚至是年为分析时间跨度的关联分析也正在成为可能。 攻击行为的长期碎片化现在有机会被关联和还原出来,大量试探性扫描和信息收集行为也能更好的与实质入侵行为区分开来,避免海量低危报警淹没了真正的高危行为。更重要的是,安全专家可以将更多原本需要人工分析和人工判定的工作交给以深度学习技术为代表的新一代机器学习和人工智能技术来处理,节省出来的人力资源和时间将可以被用在更为复杂和棘手的未知威胁检测和高危事件应急响应。除此之外,随着移动互联网和物联网技术的发展,越来越多的设备连入互联网,全天候在线设备越来越多。而移动设备、BYOD (Bring Your Own Device)的快速发展使得企业的内外网边界越来越模糊,传统的入侵检测、访问控制、防火墙等技术面临着更加复杂的挑战。 工业革命时期,水、电、交通、电信都已经实现了社会化、集约化和专业化,成为社会的公共基础设施;今天,我们处在后工业革命时期,云计算正在让信息技术和信息服务实现社会化、集约化和专业化,让信息服务成为社会的公共基础设施。越来越多的企业开始选择将其原来的内网业务搬上公有云平台,越来越多的数据开始在云计算平台上流通,这也意味着安全风险变得越来越集中。安全问题要么被消灭在萌芽阶段,要么一旦出现问题,很可能在短时间内集中爆发一大片。时间紧、任务重,就是当下信息安全防御者的最现实的概括和总结。 自动化安全防御的唯一出路就是充分挖掘大数据分析技术的能力,将大量原本需要当作个案、个例去人工分析、定制编程处理的安全事件交给“人工智能模型”去自动化分析、自动化处理。将尽可能多的任务都实现自动化处理,是避免具体安全事件中安全响应时间长的唯一选择。
数据分析、数据挖掘、机器学习、深度学习与人工智能
基于数据库系统和应用程序,可以直观查看统计分析系统中的数据,从而可以很快得到我们想要的结果,这就是最基本的数据分析。近几年随着数据规模的增长,单纯查看统计数据的方式已经无法直观的揭示出数据规律和特点,数据可视化成为新的热门数据分析技术。但相比较于数据挖掘、机器学习、深度学习和人工智能等概念和技术,数据分析的工作内容更偏重于人力资源消耗型工作,需要大量人力和手工操作来完成任务。 一个典型的利用可视化来辅助人工数据分析的例子是CyGraph: Cybersecurity Situational Awareness That’s More Scalable, Flexible & Comprehensive,如下图所示是MITRE公司的研究人员基于数据分析理念和方法,借助mongoDB、Neo4j、HDFS等工具,尝试将不同来源的网络安全数据汇总、关联分析并可视化。数据分析人员通过交互式的图匹配查询和可视化缩小数据分析范围、深入洞察数据之间的内在联系和外在特征,为解决安全问题提供了入手点。  基于这个工具的数据分析过程可以归纳总结为: 以通用形式捕获数据、根据通用模型构建分析方法,这样的方式为数据模型的扩展、变形甚至分析方法的变形(在本例中指的是图表查询)都提供了很大的灵活性。 不过一旦完成了图表查询后,你会做什么?部分工作是理解如何将问题范围表现为图表;节点是什么,关系是什么,需要捕获的属性是什么?如何对解决重要分析问题的查询作出明确表述? 上述方法虽然已经在使用数据分析的思路解决网络安全问题,但对于分析人员的专业素质水平要求会很高。同时,对于日益增长的网络数据量和报警事件数量、日益复杂的网络威胁形式,依赖分析师团队的人力分析是无法持续提供安全检测和防护能力的。让机器学习起来,让机器来代替掉更多的分析师重复工作,让分析师专注于机器暂时无法处理的高级复杂威胁的分析挖掘是一个意义重大的研究和发展方向。 根据台湾大学林轩田老师的《机器学习基石》课程中的相关概念定义:
基于这个工具的数据分析过程可以归纳总结为: 以通用形式捕获数据、根据通用模型构建分析方法,这样的方式为数据模型的扩展、变形甚至分析方法的变形(在本例中指的是图表查询)都提供了很大的灵活性。 不过一旦完成了图表查询后,你会做什么?部分工作是理解如何将问题范围表现为图表;节点是什么,关系是什么,需要捕获的属性是什么?如何对解决重要分析问题的查询作出明确表述? 上述方法虽然已经在使用数据分析的思路解决网络安全问题,但对于分析人员的专业素质水平要求会很高。同时,对于日益增长的网络数据量和报警事件数量、日益复杂的网络威胁形式,依赖分析师团队的人力分析是无法持续提供安全检测和防护能力的。让机器学习起来,让机器来代替掉更多的分析师重复工作,让分析师专注于机器暂时无法处理的高级复杂威胁的分析挖掘是一个意义重大的研究和发展方向。 根据台湾大学林轩田老师的《机器学习基石》课程中的相关概念定义:
机器学习(Machine Learning, ML)是从假设空间 H 中寻找假设函数 g 的近似目标函数 f ,数据挖掘(Data Mining / Knowledge Discovery in Database, KDD)是从 大量 的数据中寻找数据相互之间的特性。如果“有趣的属性”和“近似目标假设”一样,则机器学习=数据挖掘。如果“有趣属性”和“近似目标假设”相关,数据挖掘可以辅助机器学习,反之在大多数情况下亦然。传统的数据挖掘技术同样关注大数据集合上的有效计算问题。所以在实践中,很难严格区分数据挖掘和机器学习技术。

人工智能(Artificial Intelligence, AI)是在计算某个对象过程中表现出智能行为的技术,有很多应用领域。机器学习是实现人工智能的一种手段,但是不限于此。如果机器学习算法中得到 g ≈ f 过程表现出智能性,则该机器学习算法可以视为实现了人工智能。例如,以计算机下棋为例,经典AI算法采用的是博弈树,而用机器学习算法实现的AI算法采用的是“从棋谱数据学习”的方式。

统计学(Statistical)方法使用数据来对未知情形进行推断的过程,机器学习算法中的假设函数 g 是推断的结果, 近似目标函数 f 是属于未知情形。统计学方法可以被用于实现机器学习算法,例如:聚类、贝叶斯等等。传统统计学方法也关注“数学假设可证明”,但不太重视可计算性。统计学为机器学习提供了很多有用的工具。
 深度学习(Deep Learning, DL)和神经网络(Neural Networking, NN)都是具体的机器学习实现方法,神经网络是深度学习的基础,目前深度学习采用的主要方法就是多(隐藏)层的深度神经网络。 机器学习基本是一个方法和工具,就像数学和统计学一样。按照学习方法的差异,机器学习主要可以分为:监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)、半监督学习(Semi-supervised Learning)和强化学习(Reinforcement Learning)等。按照各自的典型用途进行分类,4大类学习方法又可以分别进一步细分为具体算法。 监督学习的主要用途是分类和回归问题,常见的分类算法有:K-近邻、决策树、朴素贝叶斯、逻辑回归、支持向量机(SVM, Support Vector Machine)、分类回归树(CART, Classification And Regression Tree)、Softmax回归等。回归问题又可以进一步细分为线性问题和非线性问题,对应线性回归算法和CART算法。 无监督学习的主要用途包括聚类问题(K-均值)、密度估计(FP-Growth算法)和关联分析(Apriori算法)。 半监督学习综合利用有标记的数据和没有标记的数据,来生成合适的分类函数,其基本思想是利用数据分布上的模型假设, 建立学习器对未标记样本进行标记。半监督学习问题从样本的角度而言是利用少量标注样本和大量未标注样本进行机器学习。 强化学习是一种“非常不同”但又十分朴素自然的学习方法,在这种学习模式下,输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式,在强化学习下,输入数据直接反馈到模型,模型必须对此立刻作出调整。常见的应用场景包括动态系统以及机器人控制等。 按照机器学习领域的领军人物吴恩达(Andrew Ng)对机器学习的定义: The science of getting computers to act without being explicitly programmed. 机器学习的最终目的就是为了把人类从重复劳动中解放出来,这对于网络安全领域目前所面临的大数据挑战而言是十分有吸引力的。
深度学习(Deep Learning, DL)和神经网络(Neural Networking, NN)都是具体的机器学习实现方法,神经网络是深度学习的基础,目前深度学习采用的主要方法就是多(隐藏)层的深度神经网络。 机器学习基本是一个方法和工具,就像数学和统计学一样。按照学习方法的差异,机器学习主要可以分为:监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)、半监督学习(Semi-supervised Learning)和强化学习(Reinforcement Learning)等。按照各自的典型用途进行分类,4大类学习方法又可以分别进一步细分为具体算法。 监督学习的主要用途是分类和回归问题,常见的分类算法有:K-近邻、决策树、朴素贝叶斯、逻辑回归、支持向量机(SVM, Support Vector Machine)、分类回归树(CART, Classification And Regression Tree)、Softmax回归等。回归问题又可以进一步细分为线性问题和非线性问题,对应线性回归算法和CART算法。 无监督学习的主要用途包括聚类问题(K-均值)、密度估计(FP-Growth算法)和关联分析(Apriori算法)。 半监督学习综合利用有标记的数据和没有标记的数据,来生成合适的分类函数,其基本思想是利用数据分布上的模型假设, 建立学习器对未标记样本进行标记。半监督学习问题从样本的角度而言是利用少量标注样本和大量未标注样本进行机器学习。 强化学习是一种“非常不同”但又十分朴素自然的学习方法,在这种学习模式下,输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式,在强化学习下,输入数据直接反馈到模型,模型必须对此立刻作出调整。常见的应用场景包括动态系统以及机器人控制等。 按照机器学习领域的领军人物吴恩达(Andrew Ng)对机器学习的定义: The science of getting computers to act without being explicitly programmed. 机器学习的最终目的就是为了把人类从重复劳动中解放出来,这对于网络安全领域目前所面临的大数据挑战而言是十分有吸引力的。
以入侵检测应用机器学习为例
基于误用的入侵检测方法的主要局限性在于:无法识别未知威胁、误用特征库维护成本高昂、误用特征数量越来越大导致实时在线匹配性能消耗越来越高等等,而基于异常的入侵检测方法能够被广泛应用于网络安全的各个细分领域其中一个重要的先验知识是:网络中恶意流量占总流量的比重是较小的,网络中恶意用户总数占总用户数的比例是较小的,网络中恶意行为占总用户行为数的比例是较小的。因此,通过观察和发现异常,可以发现威胁流量、威胁用户和威胁行为。不仅网络中如此,现实社会中总体来说各类犯罪行为占总体社会公民活动行为的比例也是极小的,这些恶意行为都可以被标记为异常行为。所以,入侵检测领域应用机器学习方法的基本思想就是:把不同来源的数据通过机器学习方法识别和分类为正常和异常。当然,对于正常和异常的进一步细分 定义 与 刻画 也可以通过机器学习方法来实现。如下图所示为基于异常的检测技术所涉及到的主要关键词及其依赖关系:  从输入数据的角度来看,输入数据可能是单变量或者多变量类型,数据属性可能包括二进制类型、枚举类型、连续型和混合型。混合型数据又被称为复杂数据类型,其可能刻画了数据之间的时空关系。数据的来源既可以是主动获取的,例如通过网络爬虫去采集威胁情报数据,通过网络扫描器去采集互联网开放端口、开放服务和漏洞信息等。数据也可以通过被动捕获获得,例如网络流量的分光镜像存储、交换机端口映射抓包、主机网卡混杂模式抓包等。除了网络流量之外,操作系统和应用软件的日志数据、网络中的数字资产信息数据等,均可以成为异常检测的输入数据。 按照输入数据是否包含标记(数据),基于异常检测的机器学习算法可以被分为监督型、半监督型和无监督型。其中如果正常数据和异常数据都有标记,则可以使用监督型学习算法;如果标记数据只有正常数据才有,异常数据缺失标记,则只能使用半监督学习算法;如果没有任何标记数据,则应该使用无监督学习算法,当然,这里暗含的数据分布假设是:异常数据在总数据中占比较少(为什么需要数据驱动安全)一节我们已经展示过了不同网络、不同用户场景下,确实恶意数据占总数据量的比例是符合较少这个条件的。因此,在入侵检测领域是有机会使用无监督学习算法的。 入侵检测领域主要涉及到的异常类型有:点数据异常、上下文信息异常和混合异常。点数据异常举例:网络中不同应用层协议流量的单个报文大小是有先验统计规律可查的,一旦发现某个已知应用层协议报文的大小不在这个经验值区间范围内,则说明该报文可能来自于一次异常网络活动流量。上下文信息异常的检测首先需要先定义正常上下文的一些特征和属性,例如工作日和节假日、工作日白天和工作日夜间的网络流量峰值变化规律是有迹可循的,而对上下文异常的定义和刻画方法很难有统一的表示方法。混合异常则较前两者异常类型要更复杂、更难以刻画和定义,例如网络中突然出现的应用层定时心跳连接、DNS的请求成功率突然降低、出现大量来自于陌生IP地址的入站和出站数据连接等。 异常检测的输出结果可能是标记(异常、正常、C&C连接、蠕虫、DDoS等)或打分(延迟决策和响应,可以进一步对打分进行排序或阈值区间筛选等)。
从输入数据的角度来看,输入数据可能是单变量或者多变量类型,数据属性可能包括二进制类型、枚举类型、连续型和混合型。混合型数据又被称为复杂数据类型,其可能刻画了数据之间的时空关系。数据的来源既可以是主动获取的,例如通过网络爬虫去采集威胁情报数据,通过网络扫描器去采集互联网开放端口、开放服务和漏洞信息等。数据也可以通过被动捕获获得,例如网络流量的分光镜像存储、交换机端口映射抓包、主机网卡混杂模式抓包等。除了网络流量之外,操作系统和应用软件的日志数据、网络中的数字资产信息数据等,均可以成为异常检测的输入数据。 按照输入数据是否包含标记(数据),基于异常检测的机器学习算法可以被分为监督型、半监督型和无监督型。其中如果正常数据和异常数据都有标记,则可以使用监督型学习算法;如果标记数据只有正常数据才有,异常数据缺失标记,则只能使用半监督学习算法;如果没有任何标记数据,则应该使用无监督学习算法,当然,这里暗含的数据分布假设是:异常数据在总数据中占比较少(为什么需要数据驱动安全)一节我们已经展示过了不同网络、不同用户场景下,确实恶意数据占总数据量的比例是符合较少这个条件的。因此,在入侵检测领域是有机会使用无监督学习算法的。 入侵检测领域主要涉及到的异常类型有:点数据异常、上下文信息异常和混合异常。点数据异常举例:网络中不同应用层协议流量的单个报文大小是有先验统计规律可查的,一旦发现某个已知应用层协议报文的大小不在这个经验值区间范围内,则说明该报文可能来自于一次异常网络活动流量。上下文信息异常的检测首先需要先定义正常上下文的一些特征和属性,例如工作日和节假日、工作日白天和工作日夜间的网络流量峰值变化规律是有迹可循的,而对上下文异常的定义和刻画方法很难有统一的表示方法。混合异常则较前两者异常类型要更复杂、更难以刻画和定义,例如网络中突然出现的应用层定时心跳连接、DNS的请求成功率突然降低、出现大量来自于陌生IP地址的入站和出站数据连接等。 异常检测的输出结果可能是标记(异常、正常、C&C连接、蠕虫、DDoS等)或打分(延迟决策和响应,可以进一步对打分进行排序或阈值区间筛选等)。
以分类为基础的异常检测技术
分类学习算法的主要思想是:,基于训练数据构建一个能分类正常(和异常)事件的模型,基于该模型可以对新的事件进行分类。需要注意的是,分类模型对输入数据的类别分布应具备较强的适应能力,应能处理输入数据(集合)可能存在的**类不平衡(class imbalance)**现象(例如网络在遭受攻击时,恶意流量占比可能会大大高于正常流量占比,而模型在训练时使用的训练数据可能恶意流量占比远远小于正常流量占比)。 伴随近几年深度学习技术火起来的神经网络算法就是一种分类学习算法,具体来说是一种包含多隐藏层的神经网络算法构建了深度学习的基础,在处理大数据集合和噪音数据时多层神经网络算法表现出了较好的健壮性和分类性能,但模型的训练时间普遍较长。除此之外,现有被广泛应用于图像识别、音频识别和生物行为识别等领域的神经网络算法普遍需要在大型监督型数据集上训练。所谓监督型数据集,即每条数据都有一个对应的标签。比如流行的 ImageNet 数据集,有一百万张人为标记的图像。一共有 1000 个类,每个类有 1000 张图像。创建这样的数据集需要花费大量的精力,同时也需要很多的时间。而在网络安全领域,类似规模的公开数据集虽然也可以找到一些,例如SecRepo.com - Samples of Security Related Data上就收集了大量包括恶意代码、网络流量、系统日志等在内的多个有标记数据集,但对于入侵检测来说,由于网络数据中可能包含真实用户隐私数据、企业内部机密数据等原因,现有的可以被用于入侵检测领域使用的公开训练数据集普遍都采用的是流量发生软硬件模拟产生的网络抓包数据或者经过匿名化处理的网络抓包数据集合甚至是已预处理好的特征工程文件,无论是数据的真实性还是数据的多样性都被打了折扣。因此,基于这些公开数据集训练出来的分类器,很难在真实网络中表现出很好的分类性能。 从规避数据标记工作量的角度出发,以聚类为基础的异常检测技术可能是未来入侵检测技术领域的一个重要研究方向。
以聚类为基础的异常检测技术
聚类学习算法能够被应用在入侵检测领域的一个关键假设就是:正常数据归属于一个规模大、密度高的集合,异常数据则不会被归属(聚类)到任何一个正常数据集合或者异常数据按照自身的相似性归属(聚类)到一个个规模小、密度低的集合。 聚类学习算法也是可以利用有标记的正常数据进行模型训练的,如果训练数据都没有标记,也没有影响,聚类算法可以正常的训练和建模。但从现阶段的研究成果来看,有监督学习算法训练出来的分类器性能要普遍优于无监督学习算法训练出来的聚类模型的分类性能,数据特征的理解和预处理对于最后的分类性能提升是有积极贡献作用的。
深度学习驱动的异常检测技术
针对入侵检测系统存在面向海量数据检测速度慢、检测性能低的问题,充分考虑深度学习在高维非线性的海量数据降维方面的优势,把深度学习算法和经典机器学习算法(如SVM、k-近邻、朴素贝叶斯算法等)结合起来构造异常检测模型是目前的一个研究热点。除此之外,如何提高深度学习平台的计算能力、缩短训练时间;选择合适的大数据处理平台(如Google的Tensorflow,微软的DMTK,Facebook的Torchnet等);开发人工智能专用芯片,提高机器学习算法运算速度;选用多服务器多GPU并行计算硬件平台,实现算法的并行化,加快模型训练速度,并且,通过扩大学习模型规模,不仅可以提升效率,也会实现更高的准确率。可以说,深度学习技术的快速发展,直接推动了异常检测技术的加快发展。 关于深度学习具体算法理论与技术实践,推荐一本免费电子书Neural Networks and Deep Learning和台湾大学林轩田老师的《机器学习基石》和《机器学习技术》,在此对具体机器学习技术就不再做展开。
评价指标与评价体系
由于异常检测的底层计算模型和算法主要来自于机器学习领域成果,因此评价一个异常检测算法好坏的方法也可以借鉴机器学习领域的通用算法评价方法和评价指标。以分类算法(输出结果是数据标记)评价为例:  在上图“分类正确性评价矩阵”(混淆矩阵,Confusion Matrix)中,在事先已知分类数据正常还是异常的前提下,经过分类器判定的数据标记可能正确,也可能会和数据实际分类有偏差。对于异常检测的输出结果是标记且标记种类只有2种的情形来说,正确的分类结果只有2种,分别是:
在上图“分类正确性评价矩阵”(混淆矩阵,Confusion Matrix)中,在事先已知分类数据正常还是异常的前提下,经过分类器判定的数据标记可能正确,也可能会和数据实际分类有偏差。对于异常检测的输出结果是标记且标记种类只有2种的情形来说,正确的分类结果只有2种,分别是:
- True Negative (TN) 数据实际分类为正常(在入侵检测领域,经验告诉我们大多数情况下获得的样本数据都是正常数据,对于正常数据我们不会产生警报,所以,negative对应的阴性输出分类就像医学诊断上的意义一样,表示正常),分类器判定输出结果也是正常;
- True Positive (TP) 数据实际分类为异常(按照上述negative在入侵检测和医学诊断领域的释义,这里用positive代表阳性结果,是需要产生报警的异常结果),分类器判定输出结果也是异常;
其他2种情况,都说明分类器判定错误,具体的错误类型分别被命名为:
- False Negative (FN) 数据实际分类为异常,分类器判定输出结果是正常。在入侵检测领域,我们将这种分类结果称为漏报;
- False Positive (FP) 数据实际分类为正常,分类器判定输出结果是异常。在入侵检测领域,我们将这种分类结果称为误报;
在明确了以上基本评价指标之后,我们先来约定以下符号表示: N=TN+FPP=TP+FN 其中,N表示所有正常(Negative)样本的总数,P表示所有异常(Positive)样本的总数。 接下来,我们可以来详细了解一下更有实际意义的一组评价指标: 真阳性率(True Positive Rate, TPR),又称为命中率(Hit Rate)、敏感度(Sensitivity),刻画了分类模型识别出的异常样本占所有异常样本的比例; 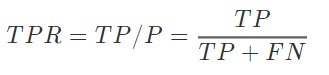 假阴性率(False Negative Rate, FPR),又称为错误命中率、误报率或虚警率(False Alarm Rate),刻画了分类模型将正常样本错误的识别为异常样本的概率;
假阴性率(False Negative Rate, FPR),又称为错误命中率、误报率或虚警率(False Alarm Rate),刻画了分类模型将正常样本错误的识别为异常样本的概率;  ROC空间将将FPR定义为X轴,TPR定义为Y轴,给定一个二元分类模型和它的阈值,就能从所有样本的(阳性/阴性)真实值和预测值计算出一个 (X=FPR, Y=TPR) 座标点。 从 (0, 0) 到 (1,1) 的对角线将ROC空间划分为左上/右下两个区域,在这条线的以上的点代表了一个好的分类结果(胜过随机分类),而在这条线以下的点代表了差的分类结果(劣于随机分类)。 完美的预测是一个在左上角的点,在ROC空间座标 (0,1) 点,X=0 代表着没有误报,Y=1 代表着没有漏报(命中率100%);也就是说,不管分类器输出结果是阳性或阴性,都是100%正确。一个随机的预测会得到位于从 (0, 0) 到 (1, 1) 对角线(也叫无识别率线)上的一个点;最直观的随机预测的例子就是抛硬币。 在实践中,对于同一组确定性样本数据,一个基于阈值参数的分类算法在设置不同阈值的情况下,FPR和TPR会随着阈值的改变而改变。将同一模型每个阈值的 (FPR, TPR) 座标都画在ROC空间里,就成为特定模型的ROC曲线。
ROC空间将将FPR定义为X轴,TPR定义为Y轴,给定一个二元分类模型和它的阈值,就能从所有样本的(阳性/阴性)真实值和预测值计算出一个 (X=FPR, Y=TPR) 座标点。 从 (0, 0) 到 (1,1) 的对角线将ROC空间划分为左上/右下两个区域,在这条线的以上的点代表了一个好的分类结果(胜过随机分类),而在这条线以下的点代表了差的分类结果(劣于随机分类)。 完美的预测是一个在左上角的点,在ROC空间座标 (0,1) 点,X=0 代表着没有误报,Y=1 代表着没有漏报(命中率100%);也就是说,不管分类器输出结果是阳性或阴性,都是100%正确。一个随机的预测会得到位于从 (0, 0) 到 (1, 1) 对角线(也叫无识别率线)上的一个点;最直观的随机预测的例子就是抛硬币。 在实践中,对于同一组确定性样本数据,一个基于阈值参数的分类算法在设置不同阈值的情况下,FPR和TPR会随着阈值的改变而改变。将同一模型每个阈值的 (FPR, TPR) 座标都画在ROC空间里,就成为特定模型的ROC曲线。  如上图所示是一个SVM算法的 ROC曲线 示意图,阈值的设定对ROC曲线的影响从这张图上可以反映出一些规律:
如上图所示是一个SVM算法的 ROC曲线 示意图,阈值的设定对ROC曲线的影响从这张图上可以反映出一些规律:
- 当阈值设定为最高时,亦即所有样本都被预测为阴性,没有样本被预测为阳性,此时在伪阳性率 FPR = FP / ( FP + TN ) 算式中的 FP = 0,所以 FPR = 0%。同时在真阳性率(TPR)算式中, TPR = TP / ( TP + FN ) 算式中的 TP = 0,所以 TPR = 0%。当阈值设定为最高时,必得出ROC座标系左下角的点 (0, 0)。
- 当阈值设定为最低时,亦即所有样本都被预测为阳性,没有样本被预测为阴性,此时在伪阳性率FPR = FP / ( FP + TN ) 算式中的 TN = 0,所以 FPR = 100%。同时在真阳性率 TPR = TP / ( TP + FN ) 算式中的 FN = 0,所以 TPR=100%。当阈值设定为最低时,必得出ROC座标系右上角的点 (1, 1)。
- 因为TP、FP、TN、FN都是累积次数,TN和FN随着阈值调低而减少(或持平),TP和FP随着阈值调低而增加(或持平),所以FPR和TPR皆必随着阈值调低而增加(或持平)。随着阈值调低,ROC点 往右上(或右/或上)移动,或不动;但绝不会往左下(或左/或下)移动。
准确率(Accuracy,一般简写为Acc)刻画了分类模型对总体样本的识别正确比例;  对于入侵检测领域来说,仅仅关注准确率(Accuracy)指标是不够的,这是因为我们在(为什么需要数据驱动安全)一节中已经探讨过很多实际场景中,异常数据占比是极小的。举一个极端的例子:假设网络流量中99.9%的数据都是正常的,只有0.1%的异常数据。那么,一个永远只会输出“正常”的分类器可以在这个网络中获得99.9%的分类“准确率”。然而,这样的分类器是没有应用价值的,因为对于“异常”数据,该分类器的检出能力(命中率和敏感度)为0。 对于分类器输出结果是标记的异常检测算法来说,评价算法分类分的准不准,主要看 精度(Precision),精度高低体现了分类模型对负样本(异常样本)的区分能力,精度越高,说明模型对负样本的区分能力越强;
对于入侵检测领域来说,仅仅关注准确率(Accuracy)指标是不够的,这是因为我们在(为什么需要数据驱动安全)一节中已经探讨过很多实际场景中,异常数据占比是极小的。举一个极端的例子:假设网络流量中99.9%的数据都是正常的,只有0.1%的异常数据。那么,一个永远只会输出“正常”的分类器可以在这个网络中获得99.9%的分类“准确率”。然而,这样的分类器是没有应用价值的,因为对于“异常”数据,该分类器的检出能力(命中率和敏感度)为0。 对于分类器输出结果是标记的异常检测算法来说,评价算法分类分的准不准,主要看 精度(Precision),精度高低体现了分类模型对负样本(异常样本)的区分能力,精度越高,说明模型对负样本的区分能力越强;  对于输出标记的分类器来说,召回率(recall)指标也是评价分类器性能的一个重要指标。召回率体现了分类模型对正样本(正常样本)的识别能力,召回率值越高,说明模型对正样本的识别能力越强。
对于输出标记的分类器来说,召回率(recall)指标也是评价分类器性能的一个重要指标。召回率体现了分类模型对正样本(正常样本)的识别能力,召回率值越高,说明模型对正样本的识别能力越强。 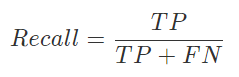 对于分类器输出结果是打分的异常检测算法来说,评价算法分类能力高低主要关注AUC(Area Under the [ROC] Curve) 值:被定义为 ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。那么AUC值的含义是什么呢?根据(Fawcett, 2006),AUC的值的含义是: the AUC of a classifier is equivalent to the probability that the classifier will rank a randomly chosen positive instance higher than a randomly chosen negative instance. 这句话有些绕,我尝试解释一下:首先AUC值是一个概率值,当你随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的打分值将这个正样本排在负样本前面的概率就是AUC值。当然,AUC值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。 除了精度、召回率和ROC,分类算法的稳定性如何则可以通过�1_F_1值来衡量。�1_F_1值就是精确率和召回率的调和均值,即:
对于分类器输出结果是打分的异常检测算法来说,评价算法分类能力高低主要关注AUC(Area Under the [ROC] Curve) 值:被定义为 ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。那么AUC值的含义是什么呢?根据(Fawcett, 2006),AUC的值的含义是: the AUC of a classifier is equivalent to the probability that the classifier will rank a randomly chosen positive instance higher than a randomly chosen negative instance. 这句话有些绕,我尝试解释一下:首先AUC值是一个概率值,当你随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的打分值将这个正样本排在负样本前面的概率就是AUC值。当然,AUC值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。 除了精度、召回率和ROC,分类算法的稳定性如何则可以通过�1_F_1值来衡量。�1_F_1值就是精确率和召回率的调和均值,即:  _F_1 值越高,说明分类模型越稳健。_F_1 值的计算公式认为精确率和召回率的权重是一样的,但在有些场景下我们可能认为精确率会更加重要,这时我们会用到 _F_1 值的一个带参数衍生形式: Fβ 值,通过调整 β 值大小可以帮助我们更好的评价分类器性能指标。
_F_1 值越高,说明分类模型越稳健。_F_1 值的计算公式认为精确率和召回率的权重是一样的,但在有些场景下我们可能认为精确率会更加重要,这时我们会用到 _F_1 值的一个带参数衍生形式: Fβ 值,通过调整 β 值大小可以帮助我们更好的评价分类器性能指标。 
2017热点 - 威胁追踪(Threat Hunting) Threat Hunting是2017年特别火的一个词,主要理念是对于威胁要积极主动、要主动出击、主动查询和追踪威胁,而不是被动等待和响应,国内社区较常见翻译为“威胁追踪”,港澳台地区较常见范围为“威胁猎杀”、“威胁狩猎”。本文采纳“威胁追踪”这个翻译,并在接下来用英文术语缩写TH来简记指代威胁追踪。 深度了解该技术之后,我们会发现其技术内核就是广泛使用了数据驱动安全的原则和技术,对该主题感兴趣的读者可以查看威胁追踪——数据驱动安全@2017一节内容。
延伸阅读
适合有python语言基础的机器学习实践入门者。
威胁追踪概述
数据驱动安全面临的挑战和机遇
数据驱动安全面临的挑战
由于机器学习在图像识别、语音识别等领域的应用已经获得显著成效,在广义信息安全领域机器学习应用已经做出了一批代表性产品,主要包括:内容安全(智能鉴黄、非法网页检测)、身份认证安全(刷脸登录)、金融交易风险控制和管理(芝麻信用、银行的风控体系)等。在这些成功案例的背后,我们也应该冷静的分析一下目前机器学习以及数据驱动安全方法论所面临的一些风险和挑战。
安全攻防领域的应用挑战
标记数据获取成本高,难度大导致网络安全领域的标记数据非常稀有:相比较于在图像识别、语音识别等领域更容易获取标记数据,安全攻防领域能标记数据的人只有安全专家,获取标记数据的人力成本和时间成本更高。 不同于真实世界的图像、语音识别处理的是从真实物体、物质经过数字化之后得到的数据,网络空间的行为识别与分类要处理的对象本身就只有数字化的载体:二进制数据。攻击者在真实世界伪造图像和语音需要经过从数字化到实体化再回到数字化的过程,而且可能还会面临一些图灵测试(例如人脸识别过程中的张嘴、转头等挑战动作检测)、真人现场监督和实时录像存档等挑战,数据伪造和污染成本较高。攻击者在网络空间伪造和污染数据更容易通过软件自动化和规模化,这对于现有机器学习算法来说是一个巨大挑战。 网络空间安全攻防手段持续更新改变,模型调参耗时赶不上。调参分类模型通常需要调很久才能够训练出来一个比较准确的模型,我们需要考虑攻防手段是不是能和花费的时间匹配上,攻击方完成一次攻击留给防御方“调参”的时间能有多少。 张钹院士在2017年7月31日在清华大学举办的“人工智能与信息安全”清华前沿论坛暨得意音通信息技术研究院成立大会上做了精彩的分享《深度学习与信息安全,如何从“事后诸葛亮”到“防患于未然”?》,其中对于AlphaGo的成功做了非常精辟的分析: Alpha Go大家讲的非常多了,有些地方宣传得有点神秘。实际上,下围棋这件事对计算机来讲是不难的,对人来讲倒有些难。为什么对计算机来讲不难呢?因为它满足以下四个条件:确定性、完全性、问题边界清晰以及有大量的数据和经验。凡是满足这四条,对计算机来讲都比较容易,尽管这个问题可能非常复杂,但是计算机处理信息的速度比人快,因此做起来比人容易。过去为什么觉得难?因为没有找到一个合适的办法,因此过去的围棋程序只能跟业余棋手下,错在我们使用下象棋的方法来下围棋。 下象棋是利用知识与经验的推理过程。马这么走,大师们能说清楚为什么这么走。围棋不然,白子为什么落在这个地方?说不清楚,这是一种棋感或直觉。所以深蓝打败了卡斯帕洛夫,不是计算机打败了人类,而是大量的大师在一起打败了一个大师,因为编制和调整象棋程序时有很多象棋高手参与,包括利用了卡斯帕洛夫过去下棋的经验,所以深蓝实际上汇聚了许多大师的智慧,包括卡斯帕洛夫的智慧在内,打败了卡斯帕洛夫。 围棋不是如此,围棋的编程人员最高的是业余五段,少数懂得一点围棋,大多数人不懂围棋。所以Alpha Go打败了李世石或其他冠军,是真正意义上机器打败了人。 对照上述4个条件关键词:确定性、完全性、问题边界清晰以及有大量的数据和经验,安全攻防领域的应用普遍无法完全具备这4个条件。机器学习算法在其他领域获得的成功,如果希望能直接复制和移植到安全攻防领域,依然需要做很多具体的测试和改进工作。
现有的机器学习算法本身依然面临一些挑战
大量的机器学习算法是在封闭静态环境中训练和测试的,数据样本属性和类别相对固定,数据样本分布基本相同,性能评价指标相对单一。这些实验室中训练好的算法一旦拿到真实场景中去应用,将面临的是开放动态环境,样本属性和类别都会有增减,样本分布会有更多变化,并且最终的性能评价指标更加多样化。以深度学习技术为代表的一大类机器学习算法目前就普遍存在着鲁棒性差或推广能力差的缺陷,当机器学会判别若干攻击方法之后,如果攻击方法稍加变化,机器就判别不了。 除此之外,对于直接拿来现成机器学习算法(特别是深度学习算法)用于安全领域应用的做法,还面临着算法黑箱,模型缺乏可解释性 。很多机器学习 算法都有算法黑箱的性质,它训练出来的模型只是有统计上的准确,并不能说它有安全意义。从软件安全的角度来看,一个既无法通过形式化描述刻画的程序,也无法通过系统化安全测试的程序,一定存在较大的系统安全风险。一旦机器做出错误的决策、错误的判断,人无法进行纠正,因为他不能理解(解释),这一点非常危险:这可能就是一种通常意义上的“错误的安全感”,与此同时,系统已经被入侵和控制、数据已经被窃取和篡改,管理员还以为天下太平。
隐私保护束缚数据获取和使用
深度学习 AI 正在或者将会变的违法。收集 28 个欧洲国家公民数据的人或公司应在 2018 年 5 月 25 日起遵循《一般数据保护条例》(GDPR),届时欧洲的一些 APP 将被禁止使用深度学习,这导致初创公司拼命寻找深度学习的替代方案,否则将面临罚款的危险。罚款金额为全球营收的 4%,包括美国部分。关于自动化决策的 GDPR 要求深度学习具有解释其决策的能力,防止基于种族、观点等的歧视的发生。类似于 GDPR 的法律已在全球广泛制定,这只是时间问题。《美国公平信用报告法》要求披露所有对消费者信用评分产生不利影响的因素,数量上限是 4 个。深度学习的因素可谓海量,而不仅仅是 4 个,如何将其简化为 4 个呢? 一方面,不管是采用哪种人工智能分析方法,采集数据、获取足够多种类和数量的数据样本是改进和提高“学习”模型的必要措施。另一方面,越来越多的国家和行业监管部门开始意识到公民个人数据除了蕴含的价值之外,还面临着严重的隐私被滥用和侵害的风险。例如,2017年8月24日,为落实网络安全法对个人信息保护的相关要求,中央网信办、工信部、公安部、国家标准委等四部门组成的专家工作组24日结束对首批10款网络产品和服务的隐私条款评审,规范其收集、保存、使用、转让用户个人信息的行为,督促整改不合法的条款。 以入侵检测领域的学术研究为例,现有的公开评测用数据集普遍使用的数据来源要么是实验室流量发生器或模拟器产生的流量,要么是经过人工筛选和匿名化处理之后的结构化数据,而真实的网络流量数据则由于担心隐私泄漏问题而无法公开分享。这就导致一方面基于这些公开数据集“学习”和建立的分类、预测模型可以获得很好的算法指标。而另一方面,由于缺少真实数据或真实数据特征维度,这些学术成果很难被直接应用于真实网络环境。
新IT形态与模式之挑战
当物联网正在把虚拟世界和真实世界相连,网络安全事件开始对真实物理世界造成很大的影响。而相比针对个人的攻击,针对国家社会基础设施的攻击会造成更恶劣的社会影响。2016年12月,乌克兰电力部门再次遭遇黑客攻击并停电30分钟。所以无论是哪个国家,在网络安全方面都在考虑如何保护包括能源、电力、交通等基础设施。物联网带来的海量设备和与之伴随的海量数据、异构软硬件架构和网络拓扑等等,必将成为数据驱动网络安全的又一个巨大挑战。
来自数据驱动黑客的对抗
不仅是安全公司、安全专家和安全研究人员在研究人工智能,使用数据驱动方法研究安全问题。我们的对手,黑产从业人员、敌对国家资助的网络军队等等也在使用相同的思路和方法。但两方力量的研究目的是针锋相对的,并且历史已经证明:攻击者总是紧跟新技术发展(甚至有时引领新技术发展)。特别是由于人工智能驱动的IT产业领域越来越多,人工智能控制了越来越多的系统,攻击者的动机越来越强。同时,人工智能的能力越来越强,攻击者滥用的后果会越来越严重。科幻小说和电影中“虚构”的人工智能被用来攻击和控制人类以及其他机器人、其他信息系统的事件,伴随数据驱动黑客的发展和成长似乎越来越有可能成为现实。为了对抗这个可能性,一些安全研究者已经开始着手研究机器学习领域的各种“对抗”问题。  如上图所示,Szegedy等人在2014年发表的论文Intriguing properties of neural networks中展示了如何欺骗一个图像识别机器学习系统将几幅完全不相关的图片全部都识别为“鸵鸟”。 Dawn Song团队在2017年发表的论文Adversarial Examples for Generative Models以MNIST手写数字识别数据集为例,展示了如何“改造”原始输入数据,使得学习模型把所有人眼看上去正常的不同数字全部识别为0。 当我们的防御方在应用机器学习的时候, 攻击方也在应用机器学习进行攻击手段的演进 。比如说有人用机器学习创建恶意软件突破防病毒系统;也有人假冒域名和注册者的关系去污染威胁情报系统,让他们的攻击被归类到另外一个组织里面。 更多关于人工智能面临的来自数据驱动黑客的挑战与应对思路的讨论,可以查看加州大学柏克莱分校 Dawn Song 在微软举办的 Faculty Summit 2017 学术峰会上关于AI 与安全的演讲,在此摘录Dawn Song关于人工智能与安全研究的4个趋势预测观点:
如上图所示,Szegedy等人在2014年发表的论文Intriguing properties of neural networks中展示了如何欺骗一个图像识别机器学习系统将几幅完全不相关的图片全部都识别为“鸵鸟”。 Dawn Song团队在2017年发表的论文Adversarial Examples for Generative Models以MNIST手写数字识别数据集为例,展示了如何“改造”原始输入数据,使得学习模型把所有人眼看上去正常的不同数字全部识别为0。 当我们的防御方在应用机器学习的时候, 攻击方也在应用机器学习进行攻击手段的演进 。比如说有人用机器学习创建恶意软件突破防病毒系统;也有人假冒域名和注册者的关系去污染威胁情报系统,让他们的攻击被归类到另外一个组织里面。 更多关于人工智能面临的来自数据驱动黑客的挑战与应对思路的讨论,可以查看加州大学柏克莱分校 Dawn Song 在微软举办的 Faculty Summit 2017 学术峰会上关于AI 与安全的演讲,在此摘录Dawn Song关于人工智能与安全研究的4个趋势预测观点:
- 如何更好的理解安全性对于AI和学习系统的意义?如何检测到学习系统已经被欺骗或攻陷?
How to better understand what security means for AI, learning systems? How to detect when a learning system has been fooled/compromised?
- 如何更好的保证构建更具弹性的系统?
How to build more resilient systems with stronger guarantees?
- 如何缓解AI滥用的风险?
How to mitigate misuse of AI?
- 确保安全AI的正确策略是什么?
What should be the right policy to ensure secure AI?
数据驱动安全面临的机遇
数据驱动安全的本质是一种高层次、跨学科的自动化手段,其内涵包括了数据分析、人工智能、大数据、云计算等等。在安全领域使用数据分析相关技术最终不是为了替代掉安全工程师职位,当然也无法替代掉(毕竟数据分析的相关算法还要依赖于人去不断改进和完善,攻击者也不会给防御者停滞不前不更新的机会)。数据分析技术作为一种重要的自动化手段,必然会消灭掉一部分简单、重复工作内容,进一步提高行业从业人员的进入门槛。在未来可以预期的很长一段时间内,数据分析都将是安全工程师和研究人员的有力工作助手。这是因为数据分析相关技术具有以下几个显著高于人力手工分析技术的特点:
- 维度高。 跟现有的安全技术团队相比,它能够关联更多的数据、更高的维度。
- 善总结。 它有很强的总结能力。通过聚类、分类或者是深度学习这样的手段,总结出历史的安全事件和历史的安全数据里面体现出来的安全规律和安全知识。
- 速度快,数量大。 它能够用更快的速度,在更短的时间内处理更大量的数据。
数据分析在安全领域应用的定位其实是一个辅助发现的手段。数据分析可以帮助我们的安全人员、安全运营者去聚焦我们所关注的领域里面的威胁,并且优化运营的效率和机制。所以数据驱动安全应该是安全研究员的瑞士军刀和安全运营者的忠实伙伴。 目前常见的数据分析流程可以归纳为:先广泛采集数据,然后深入分析数据,对数据质量有一个评估,之后把分析结果用机器的分析结果交给后台的专家进行后验。后验是为了验证算法的性能指标,并且把专家的经验进行总结,最后反馈给运营团队,让运营团队能够根据我们所发现的这些威胁、事件等进行下一步应急和主动改进现有防御体系。整个流程并不会局限于使用一种数据分析的方法,也不会限于一种数据分析相关工具和技术。专家团队的经验在这里所起到的作用可以被定义为:知识驱动安全。知识驱动方法需要知识,当你对需要解决的问题的规律了解很少,甚至不了解时,又如何做好这项工作呢?知识驱动属白盒方法,要求你对所要解决的问题有透彻的了解。数据驱动需要充分的数据,可以不需要领域知识(黑盒方法)。可是,在实际问题里,这两点(完全知识与完全数据)都很不容易达到。通常情况是掌握的知识有限,掌握的数据也有限,介乎这两者之间,我们只有通过这两种方法的结合来解决。所以,数据驱动安全是一种高层次、跨学科的自动化手段,但并不意味着能够独立支撑起整个信息安全行业方方面面的需求解决。