Git基础
概述
版本控制
版本控制是一种记录文件内容变化,以便将来查阅特定版本修订情况的系统。 版本控制其实最重要的是可以记录文件修改历史记录,从而让用户能够查看历史版本,方便版本切换。
版本控制工具
集中式版本控制工具
CVS、SVN(Subversion)、VSS…… 集中化的版本控制系统诸如 CVS、SVN 等,都有一个单一的集中管理的服务器,保存 所有文件的修订版本,而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或 者提交更新。多年以来,这已成为版本控制系统的标准做法。 这种做法带来了许多好处,每个人都可以在一定程度上看到项目中的其他人正在做些什 么。而管理员也可以轻松掌控每个开发者的权限,并且管理一个集中化的版本控制系统,要 远比在各个客户端上维护本地数据库来得轻松容易。 事分两面,有好有坏。这么做显而易见的缺点是中央服务器的单点故障。如果服务器宕机一小时,那么在这一小时内,谁都无法提交更新,也就无法协同工作。
分布式版本控制工具
Git、Mercurial、Bazaar、Darcs…… 像 Git 这种分布式版本控制工具,客户端提取的不是最新版本的文件快照,而是把代码 仓库完整地镜像下来(本地库)。这样任何一处协同工作用的文件发生故障,事后都可以用 其他客户端的本地仓库进行恢复。因为每个客户端的每一次文件提取操作,实际上都是一次 对整个文件仓库的完整备份。 分布式的版本控制系统出现之后,解决了集中式版本控制系统的缺陷:
- 服务器断网的情况下也可以进行开发(因为版本控制是在本地进行的)
- 每个客户端保存的也都是整个完整的项目(包含历史记录,更加安全)
Git 和代码托管中心
代码托管中心是基于网络服务器的远程代码仓库,一般我们简单称为远程库。 ➢ 局域网 ✓ GitLab ➢ 互联网 ✓ GitHub(外网) ✓ Gitee 码云(国内网站)
用途
代码回溯 版本切换 多人协作 远程备份
安装 Git 及环境配置
官网地址: https://git-scm.com/ 下载慢,用镜像源 Git 首次安装必须设置一下用户签名,否则无法提交代码 设置用户信息(本地)
git config --global user.name "LiAng"
git config --global user.email "xxx@xxx.com"查看配置信息
git config --list 或 git config -l
git config --system --list # 查看系统配置
git config --global --list # 查看去全局用户自己的配置Git 基本理论(核心)
Git本地有3个工作区域,工作目录(Working Directory)、暂存区(Stage/Index)、资源库(Repository或Git Directory)。如果在加上远程的git仓库(Remote Directory)就可以分为4个工作区域。 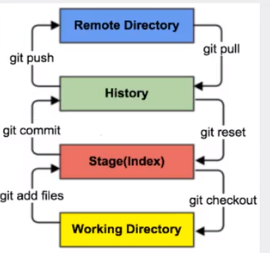
- Workspace: 工作区,就是平时存放项目代码的地方
- Index / Stage: 暂存区,用于临时存放你的改动,事实上它只是一个文件,保存即将提交到文件列表信息
- Repository: 仓库区(或本地仓库),就是安全存放数据的位置,这里面有你提交的所有版本数据。其中HEAD指向最新放入仓库的版本。
- Remote: 远程仓库,托管代码的服务器,可以简单的认为是你项目组中的一台电脑用于远程数据交换=。
Git操作流程
代码提交和同步代码
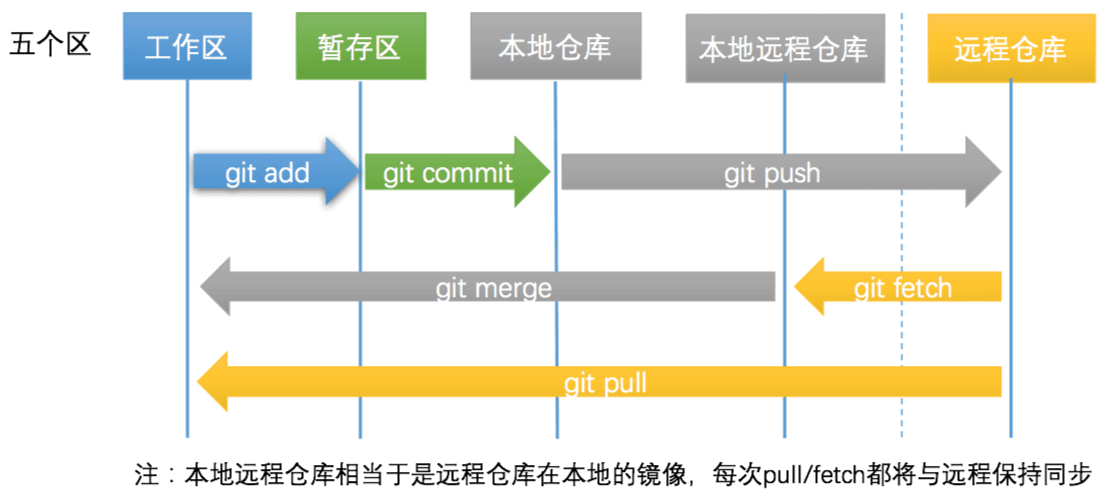 git add + git commit = git commit -a
git add + git commit = git commit -a
代码撤销和撤销同步

Git 项目搭建
创建工作目录与常用命令
工作目录一般就是你希望Git帮助你管理的文件夹,可以是项目的目录,也可以是一个空目录,建议不要有中文。 日常使用只有下面这6个命令 
方式1-本地仓库搭建
创建全新的仓库
$ git init
Initialized empty Git repository in D:/GitWork/.git/执行完后,仅仅在项目目录多出了一个.git目录,关于版本等的所有信息都在这个目录里面。
方式2-克隆远程仓库
将远程服务器上的仓库完全镜像一份至本地
git clone 远程地址Git 文件操作
4 种状态
- Untracked:未跟踪,此文件在文件夹中,但并没有加入到git库,不参与版本控制,通过 git add 使状态变为 Staged
- Unmodify:文件已经入库,未修改,即版本库中的文件快照内容与文件夹中完全一致。这种类型的文件有两种去处,如果它被修改,会变为 Modified 。 如果使用 git rm 移出版本库,则成为 Untracked 文件
- Modified:文件已修改,仅仅是修改,并没有进行其他的操作。这个文件有两个去处,通过 git add 可进入暂存 staged 状态,使用 git checkout 则丢弃修改过,返回到 unmodify 状态,这个 git checkout 即从库中取出文件,覆盖当前修改
- Staged:暂存状态。执行 git commit 则将修改同步到库中,这时库中的文件和本地文件又变为一致,文件为 unmodify 状态,执行 git reset HEAD filename 取消暂存,文件状态为 Modified
常见操作
# 查看某个文件的状态
git status [文件名]
# 查看所有文件状态
git status
# 添加所有文件到暂存区
git add .
# 提交暂存区的内容到本地仓库
git commit -m "提交信息"忽略文件
暂存区
git add 文件名 # 将已修改的文件放置暂存区
git reset 文件名 # 将暂存区的文件退回至工作区/或切换版本
git commit # 将暂存区的文件提交到本地仓库一定要先add,再commit
fatal: Not a valid object name: 'master'.
将master改名为 main
git branch -m master main如果出现 
git push --force 别名 分支名[https://blog.csdn.net/gongdamrgao/article/details/115032436](https://blog.csdn.net/gongdamrgao/article/details/115032436)学习网站
https://oschina.gitee.io/learn-git-branching/
基础指令
Git Commit
Git 仓库中的提交记录保存的是你的目录下所有文件的快照,就像是把整个目录复制,然后再粘贴一样,但比复制粘贴优雅许多!。 Git 希望提交记录尽可能地轻量,因此在你每次进行提交时,它并不会盲目地复制整个目录。条件允许的情况下,它会将当前版本与仓库中的上一个版本进行对比,并把所有的差异打包到一起作为一个提交记录。 Git 还保存了提交的历史记录。这也是为什么大多数提交记录的上面都有父节点的原因。
git commit -m "日志信息" 文件名Git Branch
Git 的分支也非常轻量。它们只是简单地指向某个提交纪录。 这是因为即使创建再多分的支也不会造成储存或内存上的开销,并且按逻辑分解工作到不同的分支要比维护那些特别臃肿的分支简单多了。
git branch 分支名 # 创建新分支
git checkout 分支名 # 切换到该分支Git Merge
如何将两个分支合并到一起。就是说我们新建一个分支,在其上开发某个新功能,开发完成后再合并回主线。 比如先切换到 Master分支,然后把 分支名 合并到 Master
git merge 分支名Git Rebase
第二种合并分支的方法是 git rebase。Rebase 实际上就是取出一系列的提交记录,“复制”它们,然后在另外一个地方逐个的放下去。 Rebase 的优势就是可以创造更线性的提交历史,这听上去有些难以理解。如果只允许使用 Rebase 的话,代码库的提交历史将会变得异常清晰。 现在在bugFix分支中,rebase到master上
git rebase master远程仓库
远程仓库并不复杂, 在如今的云计算盛行的世界很容易把远程仓库想象成一个富有魔力的东西, 但实际上它们只是你的仓库在另个一台计算机上的拷贝。你可以通过因特网与这台计算机通信 —— 也就是增加或是获取提交记录 话虽如此, 远程仓库却有一系列强大的特性 首先也是最重要的的点, 远程仓库是一个强大的备份。本地仓库也有恢复文件到指定版本的能力, 但所有的信息都是保存在本地的。有了远程仓库以后,即使丢失了本地所有数据, 你仍可以通过远程仓库拿回你丢失的数据。 还有就是, 远程让代码社交化了! 既然你的项目被托管到别的地方了, 你的朋友可以更容易地为你的项目做贡献(或者拉取最新的变更)
Git Clone
从技术上来讲,git clone 命令在真实的环境下的作用是在本地创建一个远程仓库的拷贝
git clone 远程仓库地址远程分支
远程分支反映了远程仓库(在你上次和它通信时)的状态。这会有助于你理解本地的工作与公共工作的差别 —— 这是你与别人分享工作成果前至关重要的一步. 远程分支有一个特别的属性,在你检出时自动进入分离 HEAD 状态。Git 这么做是出于不能直接在这些分支上进行操作的原因, 你必须在别的地方完成你的工作, (更新了远程分支之后)再用远程分享你的工作成果。 为什么有 o/? 你可能想问这些远程分支的前面的 o/ 是什么意思呢?好吧, 远程分支有一个命名规范 —— 它们的格式是: <remote name>/<branch name> 因此,如果你看到一个名为 o/master 的分支,那么这个分支就叫 master,远程仓库的名称就是 o。 大多数的开发人员会将它们主要的远程仓库命名为 origin,并不是 o。这是因为当你用 git clone 某个仓库时,Git 已经帮你把远程仓库的名称设置为 origin 了 不过 origin 对于我们的 UI 来说太长了,因此不得不使用简写 o 😃 但是要记住, 当你使用真正的 Git 时, 你的远程仓库默认为 origin!
Git Fetch
Git 远程仓库相当的操作实际可以归纳为两点:向远程仓库传输数据以及从远程仓库获取数据。既然我们能与远程仓库同步,那么就可以分享任何能被 Git 管理的更新(因此可以分享代码、文件、想法、情书等等)。 从远程仓库获取数据 - git fetch
git fetch 做了什么
git fetch 完成了仅有的但是很重要的两步:
- 从远程仓库下载本地仓库中缺失的提交记录
- 更新远程分支指针(如 o/master)
git fetch 实际上将本地仓库中的远程分支更新成了远程仓库相应分支最新的状态。 如果你还记得上一节课程中我们说过的,远程分支反映了远程仓库在你最后一次与它通信时的状态,git fetch 就是你与远程仓库通信的方式了! git fetch 通常通过互联网(使用 http:// 或 git:// 协议) 与远程仓库通信。
git fetch 不会做什么
git fetch 并不会改变你本地仓库的状态。它不会更新你的 master 分支,也不会修改你磁盘上的文件。 理解这一点很重要,因为许多开发人员误以为执行了 git fetch 以后,他们本地仓库就与远程仓库同步了。它可能已经将进行这一操作所需的所有数据都下载了下来,但是并没有修改你本地的文件。 所以, 你可以将 git fetch 的理解为单纯的下载操作。
Git Pull
当远程分支中有新的提交时,你可以像合并本地分支那样来合并远程分支。也就是说就是你可以执行以下命令:
git cherry-pick o/master
git rebase o/master
git merge o/master等等
实际上,由于先抓取更新再合并到本地分支这个流程很常用,因此 Git 提供了一个专门git pull来完成这两个操作。
git pull 远程库地址别名 远程分支名