爬虫小技巧
2023年11月22日大约 8 分钟约 1611 字
快速使用浏览器的请求
从浏览器请求中复制出 
curl 'https://www.twincn.com/item.aspx?no=00713302' \
-H 'authority: www.twincn.com' \
-H 'accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9' \
-H 'accept-language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6' \
-H 'cache-control: max-age=0' \
-H 'cookie: _gid=GA1.2.1033410551.1670461962; ASP.NET_SessionId=ljnhq023rpue0tgy3eqixoia; _ga_JJ8ZENTE7M=GS1.1.1670481408.38.1.1670483660.0.0.0; _gat_gtag_UA_15352051_32=1; _ga=GA1.1.1558928701.1662084209' \
-H 'sec-ch-ua: "Not?A_Brand";v="8", "Chromium";v="108", "Microsoft Edge";v="108"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "Windows"' \
-H 'sec-fetch-dest: document' \
-H 'sec-fetch-mode: navigate' \
-H 'sec-fetch-site: none' \
-H 'sec-fetch-user: ?1' \
-H 'upgrade-insecure-requests: 1' \
-H 'user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.42' \
--compressed复制到postman后,继续 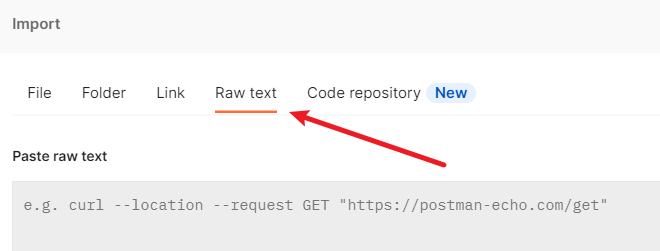

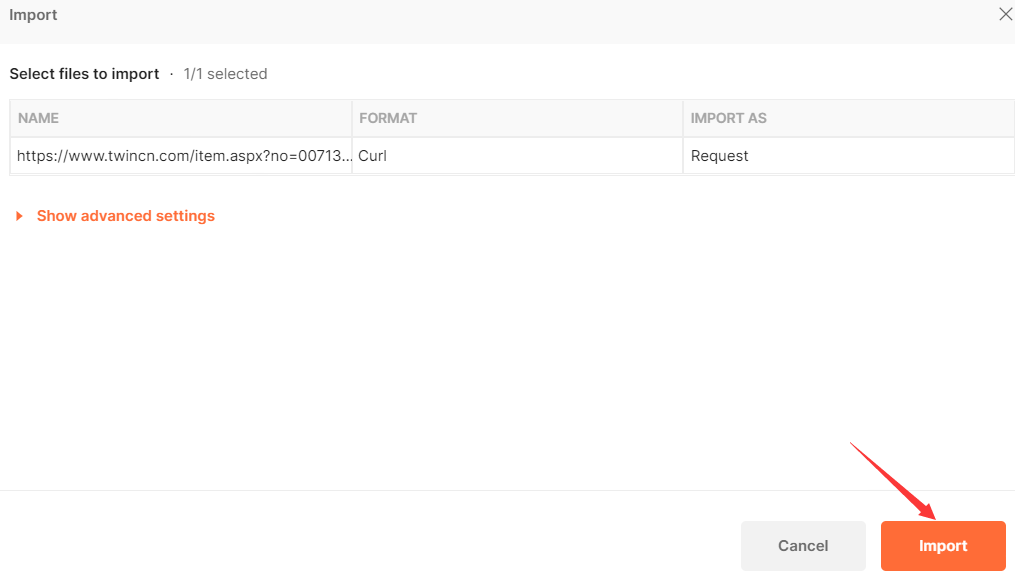 自动将参数填好了,然后发送请求,就可以得到正确response
自动将参数填好了,然后发送请求,就可以得到正确response 
导出 postman中的请求
 选择格式
选择格式  然后复制出去
然后复制出去
import requests
url = "https://www.twincn.com/item.aspx?no=00713302"
payload={}
headers = {
'authority': 'www.twincn.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'max-age=0',
'cookie': '_gid=GA1.2.1033410551.1670461962; ASP.NET_SessionId=ljnhq023rpue0tgy3eqixoia; _ga_JJ8ZENTE7M=GS1.1.1670481408.38.1.1670483660.0.0.0; _gat_gtag_UA_15352051_32=1; _ga=GA1.1.1558928701.1662084209',
'sec-ch-ua': '"Not?A_Brand";v="8", "Chromium";v="108", "Microsoft Edge";v="108"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.42'
}
response = requests.request("GET", url, headers=headers, data=payload)
print(response.text)Scrapy提升性能
https://www.cnblogs.com/lanston1/p/11902158.html
Scrapy中写日志记录
settings中配置log

import datetime
to_day = datetime.datetime.now()
# 年月日时分秒
log_file_path = 'log/scrapy_{}_{}_{}_{}_{}_{}'.format(
to_day.year, to_day.month, to_day.day, to_day.hour, to_day.minute, to_day.second)
LOG_LEVEL = 'WARNING'
LOG_FILE = log_file_pathScrapy日志
https://www.yiibai.com/scrapy/scrapy_logging.html
自己写了个单例logger
import logging
import logging.handlers
import datetime
class Custom_logger(object):
_instance = None
def __new__(cls, *args, **kwargs):
if not cls._instance:
logger = logging.getLogger('自定义日志处理器')
logger.setLevel(logging.INFO)
consoleHandler = logging.StreamHandler()
consoleHandler.setLevel(logging.INFO)
to_day = datetime.datetime.now()
# log路径 年月日时分秒
log_file_path = 'log/scrapy_{}_{}_{}_{}_{}.log'.format(to_day.year, to_day.month, to_day.day, to_day.hour, to_day.minute)
fileHandler = logging.FileHandler(filename=log_file_path, encoding='utf-8')
fileHandler.setLevel(logging.WARNING)
formatter = logging.Formatter("%(asctime)s|%(levelname)8s|%(filename)10s%(lineno)s|%(message)s", datefmt="%Y-%m-%d %H:%M:%S")
# 给处理器设置格式
consoleHandler.setFormatter(formatter)
fileHandler.setFormatter(formatter)
# 记录器要设置处理器
logger.addHandler(consoleHandler)
logger.addHandler(fileHandler)
cls._instance = logger
return cls._instance
custom_logger = ''
# 测试用
if __name__ == '__main__':
a = Custom_logger()
b = Custom_logger()
print(a == b)
print('...')在程序中导入logging模块,对需要输出的内容进行log日志输出
logging的使用https://www.yuque.com/liang-znkb8/eot3gg/vgip043yov4sgf0u#QDeGb
下载文件
下载大文件
流式分块下载 原理:一块一块地将内存写入到文件中,以避免内存占用过大。 
# 流式下载大文件
def stream_download(name,url, headers):
cookie = {
'__ddgid_': 'wyXuMuyQDyVwffJS',
'__ddgmark_': 'nl7wnLqqyVlXNcZ0',
'__ddg2_': 'diw7T8jQlLHoPdAx',
'__ddg3': '5mUPW7OSTZg7Ugbz',
'__ddg1_': 'xLiwXew1WsNqwdIidKwu',
'mybb[lastvisit]': '1670755744',
'mybb[lastactive]': '1670757548',
'mybbuser': '251400_dpEqvR2ItQwiBjfhfTbDd2Q2yMuKtzYF9eYMYQppG6pe3DxlOW',
'mybb[announcements]': '0',
'sid': '0cdf0a907830de1fcde7f5caeae27e7b'
}
# 获取响应
response = requests.get(url,stream=True, headers=headers, cookies=cookie)
with open('free_database/'+name+'.7z', 'wb') as file:
for chunk in response.iter_content(chunk_size=1024):
# 每1024个字节进行读取
if chunk:
# chunk不为空
file.write(chunk)显示下载速度和百分比
# coding: utf-8
# -*- coding: utf-8 -*-
import time
import requests
def onefloat(num):
return '{:.1f}'.format(num)
def run():
# 请求下载地址,以流式的。打开要下载的文件位置。
with requests.get('https://vault.centos.org/5.0/updates/SRPMS/autofs-5.0.1-0.rc2.43.0.2.src.rpm', stream=True) as r, open(r'G:\work\autofs-5.0.1-0.rc2.43.0.2.src.rpm', 'wb') as file:
# 请求文件的大小单位字节B
total_size = int(r.headers['content-length'])
print(total_size)
# 以下载的字节大小
content_size = 0
# 进度下载完成的百分比
plan = 0
# 请求开始的时间
start_time = time.time()
# 上秒的下载大小
temp_size = 0
# 开始下载每次请求1024字节
for content in r.iter_content(chunk_size=1024):
file.write(content)
# 统计以下载大小
content_size += len(content)
# 计算下载进度
plan = (content_size / total_size) * 100
# 每一秒统计一次下载量
if time.time() - start_time > 1:
# 重置开始时间
start_time = time.time()
# 每秒的下载量
speed = content_size - temp_size
# KB级下载速度处理
if 0 <= speed < (1024 ** 2):
print('\r', onefloat(plan), '%', onefloat(speed / 1024), 'KB/s', end='', flush=True)
# MB级下载速度处理
elif (1024 ** 2) <= speed < (1024 ** 3):
print('\r', onefloat(plan), '%', onefloat(speed / (1024 ** 2)), 'MB/s', end='', flush=True)
# GB级下载速度处理
elif (1024 ** 3) <= speed < (1024 ** 4):
print('\r', onefloat(plan), '%', onefloat(speed / (1024 ** 3)), 'GB/s', end='', flush=True)
# TB级下载速度处理
else:
print('\r', onefloat(plan), '%', onefloat(speed / (1024 ** 4)), 'TB/s', end='', flush=True)
# 重置以下载大小
temp_size = content_size
run()将上面两个整合一下
# 流式下载大文件
def stream_download(name,url, headers):
cookie = {
'__ddgid_': 'wyXuMuyQDyVwffJS',
'__ddgmark_': 'nl7wnLqqyVlXNcZ0',
'__ddg2_': 'diw7T8jQlLHoPdAx',
'__ddg3': '5mUPW7OSTZg7Ugbz',
'__ddg1_': 'xLiwXew1WsNqwdIidKwu',
'mybb[lastvisit]': '1670755744',
'mybb[lastactive]': '1670757548',
'mybbuser': '251400_dpEqvR2ItQwiBjfhfTbDd2Q2yMuKtzYF9eYMYQppG6pe3DxlOW',
'mybb[announcements]': '0',
'sid': '0cdf0a907830de1fcde7f5caeae27e7b'
}
# 获取响应
response = requests.get(url,stream=True, headers=headers, cookies=cookie)
with open('free_datas/'+name+'.7z', 'wb') as file:
# 请求文件的大小单位字节B
total_size = int(response.headers['content-length'])
print(name,' 文件大小: ',total_size)
# 以下载的字节大小
content_size = 0
# 进度下载完成的百分比
plan = 0
# 请求开始的时间
start_time = time.time()
# 上秒的下载大小
temp_size = 0
for content in response.iter_content(chunk_size=1024):
# 每1024个字节进行读取
if content:
# chunk不为空
file.write(content)
# 统计以下载大小
content_size += len(content)
# 计算下载进度
plan = (content_size / total_size) * 100
# 每一秒统计一次下载量
if time.time() - start_time > 1:
# 重置开始时间
start_time = time.time()
# 每秒的下载量
speed = content_size - temp_size
# KB级下载速度处理
if 0 <= speed < (1024 ** 2):
print('\r', onefloat(plan), '%', onefloat(speed / 1024), 'KB/s', end='', flush=True)
# MB级下载速度处理
elif (1024 ** 2) <= speed < (1024 ** 3):
print('\r', onefloat(plan), '%', onefloat(speed / (1024 ** 2)), 'MB/s', end='', flush=True)
# GB级下载速度处理
elif (1024 ** 3) <= speed < (1024 ** 4):
print('\r', onefloat(plan), '%', onefloat(speed / (1024 ** 3)), 'GB/s', end='', flush=True)
# TB级下载速度处理
else:
print('\r', onefloat(plan), '%', onefloat(speed / (1024 ** 4)), 'TB/s', end='', flush=True)
# 重置以下载大小
temp_size = content_size
def onefloat(num):
return '{:.1f}'.format(num)
下载多个文件
问题
pycharm:无法加载文件activate.ps1,因为在此系统上禁止运行脚本
pycharm编译运行Python代码时候报错,原因是Windows新的权限执行策略改变。在PowerShell里面执行命令:
Get-ExecutionPolicy输出的是 Restricted 表明当前是严格受限模式,需要设置打开,在PowerShell里面执行命令:
Set-ExecutionPolicy Bypass重启pycharm即可解决问题
查看linux文件个数
查看linux目录下的文件个数(不包括文件夹)
ls -l | grep "^-" | wc -l统计当前目录下文件的个数(包括子目录)
ls -lR | grep "^-" | wc -l