分布式爬虫案例
2023年11月23日大约 8 分钟约 1550 字
linux的安装
最小化安装即可
linux的软件安装配置
yum install net-tools
yum -y install lrzsz //安装 rz
vim /etc/sysconfig/network-scripts/ifcfg-ens33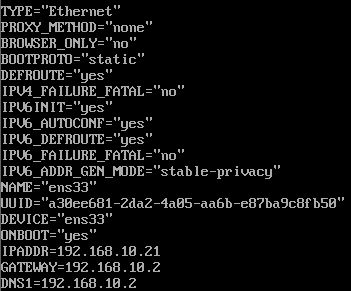
systemctl restart network安装python
详见 https://note.youdao.com/s/AbmQOD2S
分布式环境
base1,base2不用安装图形化界面
安装scrapy,scrapy-redis
yum install -y wget //向迅雷一样的东西
pip3 install scrapy
pip3 install scrapy-redis此时环境安装的差不多了,准备克隆 克隆前
vim /etc/sysconfig/network-scripts/ifcfg-ens33
删除UUID拍摄快照 



 克隆完记得修改网络配置文件
克隆完记得修改网络配置文件 
base0安装图形化界面
修改网络配置文件
BOOTPROTO="static"
IPADDR=192.168.10.20
GATEWAY=192.168.10.2
DNS1=192.168.10.2准备工作:下载安装最新版的 gcc 编译器
[root@base0 opt]# yum install gcc
//测试 gcc 版本
[root@base0 opt]# gcc --version
gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44)
Copyright © 2015 Free Software Foundation, Inc.
本程序是自由软件;请参看源代码的版权声明。本软件没有任何担保;
包括没有适销性和某一专用目的下的适用性担保。安装python,srcapy和scrapy-redis,上面有
安装redis
上传压缩包到 /opt
[root@base0 opt]# ls
redis-6.2.1.tar.gz rh//解压
[root@base0 opt]# tar -zxf redis-6.2.1.tar.gz
[root@base0 opt]# cd redis-6.2.1/
[root@base0 redis-6.2.1]# make如果没有准备好 C 语言编译环境,make 会报错—Jemalloc/jemalloc.h:没有那个文件 解决方案:运行 make distclean 在 redis-6.2.1 目录下再次执行 make 命令(只是编译好)
[root@base0 redis-6.2.1]# make install
cd src && make install
make[1]: 进入目录“/opt/redis-6.2.1/src”
CC Makefile.dep
make[1]: 离开目录“/opt/redis-6.2.1/src”
make[1]: 进入目录“/opt/redis-6.2.1/src”
Hint: It's a good idea to run 'make test' ;)
INSTALL install
INSTALL install
INSTALL install
make[1]: 离开目录“/opt/redis-6.2.1/src”安装目录:/usr/local/bin
[root@localhost redis-6.2.1]# cd /usr/local/bin
[root@base0 bin]# ls
redis-benchmark redis-check-rdb redis-sentinel
redis-check-aof redis-cli redis-serverredis-benchmark:性能测试工具,可以在自己本子运行,看看自己本子性能如何 redis-check-aof:修复有问题的 AOF 文件 redis-check-dump:修复有问题的 dump.rdb 文件 redis-sentinel:Redis 集群使用 redis-server:Redis 服务器启动命令 redis-cli:客户端,操作入口
前台启动(不推荐)
前台启动,命令行窗口不能关闭,否则服务器停止
[root@base0 bin]# redis-server
后台启动(推荐)
备份 redis.conf
[root@base0 redis-6.2.1]# pwd
/opt/redis-6.2.1
[root@base0 redis-6.2.1]# cp redis.conf /etc/redis.conf后台启动设置 daemonize no 改成 yes
[root@base0 redis-6.2.1]# cd /etc
[root@base0 etc]# vi redis.conf
启动redis
[root@base0 etc]# cd /usr/local/bin
[root@base0 bin]# ls
dump.rdb redis-check-aof redis-cli redis-server
redis-benchmark redis-check-rdb redis-sentinel
[root@base0 bin]# redis-server /etc/redis.conf
[root@base0 bin]# ps -ef | grep redis
root 10656 1 0 15:25 ? 00:00:00 redis-server 127.0.0.1:6379
root 10662 3941 0 15:26 pts/1 00:00:00 grep --color=auto redis
//客户端访问redis
[root@base0 bin]# redis-cli
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> exit
[root@base0 bin]#redis.conf 还要修改
[root@base0 bin]# cd /etc
[root@base0 etc]# vi redis.conf
# 注释该行,表示可以让其他ip访问redis
# bind 127.0.0.1 -::1
# 将yes改为no: 表示可以让其他ip操作redis
protected-mode noSQLite3,Scrapyd,Gerapy安装
base0上需要安装这三个,base1和base2只需要安装Scrapyd https://note.youdao.com/s/GnYDKqBY
例子
scrapy startproject twljx
进入到项目
scrapy genspider company -t crawl twincn.com创建 company.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class CompanySpider(CrawlSpider):
name = 'company'
allowed_domains = ['twincn.com']
start_urls = ['https://www.twincn.com/dir.aspx?a1=55&a2=64']
rules = (
Rule(LinkExtractor(restrict_xpaths=r'//div[@class="row"]//td/a'), callback='parse_item', follow=True),
)
def parse_item(self, response):
# https://www.twincn.com /item.aspx?no=90339377
company = response.xpath('//div[@class="row"]/table//td/a/@href').extract_first()
yield {
"company": company
}修改 settings.py
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36 Edg/105.0.1343.50'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 1创建 start.py
from scrapy.cmdline import execute
execute("scrapy crawl company".split())运行测试
修改 company.py
from scrapy_redis.spiders import RedisCrawlSpider
class CompanySpider(RedisCrawlSpider):
name = 'company'
allowed_domains = ['twincn.com']
# start_urls = ['https://www.twincn.com/dir.aspx?a1=55&a2=64']
redis_key = 'company:start_urls'修改 settings.py
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400,
}
# redis所在linux的ip
REDIS_HOST = '192.168.10.20'
REDIS_PORT = 6379将该项目文件夹放到linux

 在base0上(安装有redis的)访问redis
在base0上(安装有redis的)访问redis
[root@base0 ~]# redis-cli
127.0.0.1:6379> lpush company:start_urls https://www.twincn.com/dir.aspx?a1=55&a2=64
(integer) 1下面的操作,base1和base2都需要操作
[root@base1 opt]# ls
Python-3.7.10 Python-3.7.10.tgz twljx
[root@base1 opt]# cd twljx/
[root@base1 twljx]# cd twljx/
[root@base1 twljx]# cd spiders/
[root@base1 spiders]# ls
company.py __init__.py __pycache__
[root@base1 spiders]# scrapy runspider company.py爬取结果
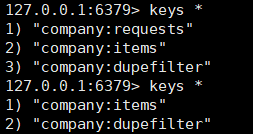
127.0.0.1:6379> type company:items
list
从redis中取出数据,保存到MongoDB
布隆过滤器
爬取台湾公司网
修改成分布式 RedisCrawlSpider
修改company_spider.py
from scrapy_redis.spiders import RedisCrawlSpider
class CompanySpiderSpider(RedisCrawlSpider):
name = 'company_spider'
allowed_domains = ['twincn.com']
# start_urls = ['https://www.twincn.com']
redis_key = 'company:start_url'修改 settings.py
# 增加了一个去重容器类的配置, 作用使用Redis的set集合来存储请求的指纹数据, 从而实现请求去重的持久化
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy-redis组件自己的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 配置调度器是否要持久化, 也就是当爬虫结束了, 要不要清空Redis中请求队列和去重指纹的set。如果是True, 就表示要持久化存储, 就不清空数据, 否则清空数据
SCHEDULER_PERSIST = True
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400,
}
REDIS_HOST = '192.168.10.20'
REDIS_PORT = 6379
# REDIS_ENCODING ='utf-8'
# REDIS_PARAMS = {'password':'xx'}redis放入key
lpush company:start_url https://www.twincn.com把该项目文件夹放进linux
切换目录运行
base2同样操作
[root@base1 scrapy_project]# cd twincn_distributed/twincn/spiders/
[root@base1 spiders]# pwd
/root/scrapy_project/twincn_distributed/twincn/spiders
[root@base1 spiders]# ls
company_spider.py __init__.py __pycache__ start.py
[root@base1 spiders]# scrapy runspider company_spider.py遇到的问题
No module named '_lzma'

# centos系统执行
yum install xz-devel -y
yum install python-backports-lzma -y
pip3 install backports.lzma
# ubuntu系统执行
apt-get install liblzma-dev -y
pip install backports.lzma修改lzma.py文件
[root@base1 lib]# vim /usr/local/Python-3.7.10/lib/python3.7/lzma.py代码如下
try:
from _lzma import *
from _lzma import _encode_filter_properties, _decode_filter_properties
except ImportError:
from backports.lzma import *
from backports.lzma import _encode_filter_properties, _decode_filter_properties连接Redis出现No route to host
 解决:https://blog.csdn.net/wwwlxz/article/details/39859181
解决:https://blog.csdn.net/wwwlxz/article/details/39859181