大数据常用环境搭建
准备工作
(1)Linux系统必须是图形化界面 (2)关闭防火墙,关闭防火墙开机自启 [root@hadoop102 ~]# systemctl stop firewalld[root@hadoop102 ~]# systemctl disable firewalld.service (3)创建 lzw 用户,并修改密码 [root@hadoop102 ~]# useradd lzw[root@hadoop102 ~]# passwd 123456 (4)配置lzw用户具有root权限,方便后期加sudo执行root权限的命令 [root@hadoop102 ~]# vim /etc/sudoers
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
lzw ALL=(ALL) NOPASSWD:ALL (5)在/opt目录下创建文件夹,并修改所属主和所属组
(5)在/opt目录下创建文件夹,并修改所属主和所属组 [root@hadoop102 ~]# mkdir /opt/module[root@hadoop102 ~]# mkdir /opt/software 修改module、software文件夹的所有者和所属组均为lzw用户 [root@hadoop102 ~]# chown lzw:lzw /opt/module[root@hadoop102 ~]# chown lzw:lzw /opt/software (6)网络配置 [root@hadoop102 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
DEVICE=ens33
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
NAME="ens33"
IPADDR=192.168.10.102 # 192.168.10.103,192.168.10.104
PREFIX=24
GATEWAY=192.168.10.2
DNS1=192.168.10.2(7)修改主机名 [root@hadoop102 ~]# vim /etc/hostname hadoop102 (8)配置Linux克隆机主机名称映射hosts文件 [root@hadoop102 ~]# vim /etc/hosts
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104重启虚拟机 [root@hadoop102 ~]# reboot (9)修改windows的主机映射文件(hosts文件) C:\Windows\System32\drivers\etc路径 添加如下内容
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104JDK环境
将jar包传输到linux中
[lzw@hadoop102 ~]$ ls /opt/software/ 看到如下结果 jdk-8u212-linux-x64.tar.gz 切换到该目录 [lzw@hadoop102 ~]$ cd /opt/software/
解压JDK到/opt/module目录下
[lzw@hadoop102 software]$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module
配置JDK环境变量
新建/etc/profile.d/my_env.sh文件 [lzw@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh 添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin保存后退出,source一下/etc/profile文件,让新的环境变量PATH生效 [lzw@hadoop102 ~]$ source /etc/profile
测试JDK是否安装成功
[lzw@hadoop102 ~]$ java -version 如果能看到以下结果,则代表Java安装成功。 java version "1.8.0_212"
Hadoop环境
将jar包传输到linux中
进入到该目录 [lzw@hadoop102 ~]$ cd /opt/software/
解压安装文件到/opt/module下面
[lzw@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/ 查看是否解压成功 [lzw@hadoop102 software]$ ls /opt/module/hadoop-3.1.3
配置Hadoop环境变量
[lzw@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh 在文件末尾添加如下内容
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin保存后退出,source一下/etc/profile文件,让新的环境变量PATH生效 [lzw@hadoop102 ~]$ source /etc/profile
测试是否安装成功
[lzw@hadoop102 ~]$ hadoop version Hadoop 3.1.3
集群分发脚本xsync
需求:循环复制文件到所有节点的相同目录下。(脚本在任何路径都能使用)
在 /home/lzw/bin 目录下创建xsync文件
[lzw@hadoop102 opt]$ cd /home/lzw[lzw@hadoop102 ~]$ mkdir bin[lzw@hadoop102 ~]$ cd bin[lzw@hadoop102 bin]$ vim xsync
在该文件中编写如下代码
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done修改脚本 xsync 具有执行权限
[lzw@hadoop102 bin]$ chmod 777 xsync 测试脚本 [lzw@hadoop102 ~]$ xsync /home/lzw/bin
将脚本复制到/bin中,以便全局调用
[lzw@hadoop102 bin]$ sudo cp xsync /bin/
同步环境变量配置(root所有者)
[lzw@hadoop102 ~]$ sudo ./bin/xsync /etc/profile.d/my_env.sh 让环境变量生效 [lzw@hadoop103 bin]$ source /etc/profile[lzw@hadoop104 bin]$ source /etc/profile
SSH免密登录
生成公钥和私钥
[lzw@hadoop102 .ssh]$ pwd /home/lzw/.ssh[lzw@hadoop102 .ssh]$ ssh-keygen -t rsa 然后敲三次回车,就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥) [lzw@hadoop102 .ssh]$ ssh-copy-id hadoop102[lzw@hadoop102 .ssh]$ ssh-copy-id hadoop103[lzw@hadoop102 .ssh]$ ssh-copy-id hadoop104
注意
还需要在hadoop103上采用lzw账号配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。 还需要在hadoop104上采用lzw账号配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。 还需要在hadoop102上采用root账号,配置一下无密登录到hadoop102、hadoop103、hadoop104。
| known_hosts | 记录ssh访问过计算机的公钥(public key) |
|---|---|
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过的无密登录服务器公钥 |
集群配置
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
注意: (1)NameNode和SecondaryNameNode不要安装在同一台服务器 (2)ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
配置 core-site.xml
[lzw@hadoop102 hadoop]# pwd /opt/module/hadoop-3.1.3/etc/hadoop[lzw@hadoop102 hadoop]$ vim core-site.xml 文件内容如下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property>
</configuration>配置 hdfs-site.xml
[lzw@hadoop102 hadoop]$ vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>配置 yarn-site.xml
[lzw@hadoop102 hadoop]$ vim yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>配置 mapred-site.xml
[lzw@hadoop102 hadoop]$ vim mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>在集群上分发配置好的Hadoop配置文件
[lzw@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/ 再分别看看103,104的分发情况
群起集群
配置workers
[lzw@hadoop102 hadoop]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
hadoop102
hadoop103
hadoop104注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。 同步所有节点配置文件 [lzw@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc
启动集群
(1)如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。) [lzw@hadoop102 hadoop-3.1.3]$ hdfs namenode -format (2)启动HDFS [lzw@hadoop102 hadoop-3.1.3]$ start-dfs.sh (3)**在配置了ResourceManager的节点(hadoop103)**启动YARN [lzw@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh (4)Web端查看HDFS的NameNode 浏览器中输入:http://hadoop102:9870 (5)Web端查看YARN的ResourceManager 浏览器中输入:http://hadoop103:8088 注意:浏览器可以直接使用hadoop102,因为已经修改过hosts文件。
配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。
配置mapred-site.xml
[lzw@hadoop102 hadoop]$ vim mapred-site.xml
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>分发配置
[lzw@hadoop102 hadoop]$ xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml
在hadoop102启动历史服务器
[lzw@hadoop102 hadoop]$ mapred --daemon start historyserve
查看历史服务器是否启动
[lzw@hadoop102 hadoop]$ jps
查看JobHistory
浏览器输入:http://hadoop102:19888/jobhistory
配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。  注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
配置 yarn-site.xml
[lzw@hadoop102 hadoop]$ vim yarn-site.xml
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>分发配置
[lzw@hadoop102 hadoop]$ xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml
关闭NodeManager 、ResourceManager和HistoryServer
[lzw@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh[lzw@hadoop103 hadoop-3.1.3]$ mapred --daemon stop historyserver
启动NodeManager 、ResourceManage和HistoryServer
[lzw@hadoop103 ~]$ start-yarn.sh[lzw@hadoop102 ~]$ mapred --daemon start historyserver
编写Hadoop集群常用脚本
Hadoop集群启停脚本
(包含HDFS,Yarn,Historyserver):myhadoop.sh [lzw@hadoop102 ~]$ cd /home/lzw/bin[lzw@hadoop102 bin]$ vim myhadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac保存后退出,然后赋予脚本执行权限 [lzw@hadoop102 bin]$ chmod 777 myhadoop.sh 使用演示 [lzw@hadoop102 bin]$ myhadoop.sh start
查看三台服务器Java进程脚本:jpsall
[lzw@hadoop102 ~]$ cd /home/lzw/bin[lzw@hadoop102 bin]$ vim jpsall
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps
done保存后退出,然后赋予脚本执行权限 [lzw@hadoop102 bin]$ chmod 777 jpsal
分发/home/lzw/bin目录,保证自定义脚本在三台机器上都可以使用
[lzw@hadoop102 ~]$ xsync /home/lzw/bin/
常用端口号说明
| 端口名称 | Hadoop2.x | Hadoop3.x |
|---|---|---|
| NameNode内部通信端口 | 8020 / 9000 | 8020 / 9000/9820 |
| NameNode HTTP UI | 50070 | 9870 |
| MapReduce查看执行任务端口 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |
Zookeeper环境
将jar包传输到linux中
进入到该目录 [lzw@hadoop102 ~]$ cd /opt/software/
解压安装文件到/opt/module下面
[lzw@hadoop102 software]$ tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/ 查看是否解压成功 [lzw@hadoop102 software]$ ls /opt/module/ 修改名称 [lzw@hadoop102 module]$ mv apache-zookeeper-3.5.7-bin zookeeper-3.5.7
配置服务器编号
(1)在/opt/module/zookeeper-3.5.7/这个目录上创建 zkData 文件夹 [lzw@hadoop102 zookeeper-3.5.7]$ mkdir zkData (2)在/opt/module/zookeeper-3.5.7/zkData 目录下创建一个 myid 的文件 [lzw@hadoop102 zkData]$ vi myid 在文件中添加与 server 对应的编号(注意:上下不要有空行,左右不要有空格)
2(3)拷贝配置好的 zookeeper 到其他机器上 [lzw@hadoop102 module ]$ xsync zookeeper-3.5.7 并分别在 hadoop103、hadoop104 上修改 myid 文件中内容为 3、4
配置zoo.cfg文件
(1)将/opt/module/zookeeper-3.5.7/conf 这个路径下的 zoo_sample.cfg 修改为 zoo.cfg; [lzw@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg (2)打开 zoo.cfg 文件,修改 dataDir 路径: [lzw@hadoop102 zookeeper-3.5.7]$ vim zoo.cfg
dataDir=/opt/module/zookeeper-3.5.7/zkData在文件最下面增加如下配置
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888(3)同步 zoo.cfg 配置文件 [lzw@hadoop102 conf]$ xsync zoo.cfg (4)集群操作 分别启动Zookeeper [lzw@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start[lzw@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh start[lzw@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh start 查看状态 [lzw@hadoop102 zookeeper-3.5.7]# bin/zkServer.sh status JMX enabled by default Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg Mode: follower[lzw@hadoop103 zookeeper-3.5.7]# bin/zkServer.sh status JMX enabled by default Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg Mode: leader[lzw@hadoop104 zookeeper-3.5.7]# bin/zkServer.sh status JMX enabled by default Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg Mode: follower
ZK集群启动停止脚本
在 hadoop102 的/home/lzw/bin 目录下创建脚本
[lzw@hadoop102 bin]$ vim zk.sh
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh
start"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh
stop"
done
};;
"status"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh
status"
done
};;
esac增加脚本执行权限
[lzw@hadoop102 bin]$ chmod u+x zk.sh
Zookeeper 集群启动脚本
[lzw@hadoop102 module]$ zk.sh start
Zookeeper 集群停止脚本
[lzw@hadoop102 module]$ zk.sh stop
启动客户端
hadoop102客户端 [lzw@hadoop102 zookeeper-3.5.7]$bin/zkCli.sh -server hadoop102:2181 本地客户端 [lzw@hadoop102 zookeeper-3.5.7]$bin/zkCli.sh
Hive环境
将jar包传输到linux中
 进入到该目录
进入到该目录 [lzw@hadoop102 ~]$ cd /opt/software/
解压安装文件到/opt/module下面
[lzw@hadoop102 software]$ tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/ 查看是否解压成功 [lzw@hadoop102 software]$ ls /opt/module/ 修改名称 [lzw@hadoop102 module]$ mv apache-hive-3.1.2-bin hive
配置Hive环境变量
[lzw@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh 在文件末尾添加如下内容
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin保存后退出,source一下/etc/profile文件,让新的环境变量PATH生效 [lzw@hadoop102 ~]$ source /etc/profile
解决日志 Jar 包冲突(可选)
[lzw@hadoop102 software]$ mv $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.jar $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.bak
初始化元数据库
[lzw@hadoop102 hive]$ bin/schematool -dbType derby -initSchemaInitialization script completed schemaTool completed
启动Hive
必须先启动Hadoop [lzw@hadoop102 hive]$ bin/hive
MySQL安装
卸载 mariadb
[lzw@hadoop102 ~]$ rpm -qa|grep mariadb mariadb-libs-5.5.56-2.el7.x86_64 卸载 [lzw@hadoop102 ~]$ sudo rpm -e --nodeps mariadb-libs
解压MySQL安装包
[lzw@hadoop102 software]$ tar -xf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
在安装目录下执行 rpm 安装
[lzw@hadoop102 software]$
sudo rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm初始化数据库
[lzw@hadoop102 opt]$ sudo mysqld --initialize --user=mysql
查看临时生成的 root 用户的密码
[lzw@hadoop102 opt]$ sudo cat /var/log/mysqld.log
启动MySQL服务
[lzw@hadoop102 opt]$ sudo systemctl start mysqld[lzw@hadoop102 opt]$ mysql -uroot -p Enter password: 输入临时生成的密码
修改 root 用户的密码
mysql> set password = password("新密码");
修改 mysql 库下的 user 表中的 root 用户允许任意 ip 连接
mysql> update mysql.user set host='%' where user='root';mysql> flush privileges;
Hive 元数据配置到 MySQL
拷贝驱动
将 MySQL 的 JDBC 驱动拷贝到 Hive 的 lib 目录下 [lzw@hadoop102 hive]$ cp /opt/software/mysql-connector-java-5.1.27-bin.jar ./lib/
配置 Metastore 到 MySQL
[lzw@hadoop102 hive]$ cd conf[lzw@hadoop102 conf]$ vim hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc 连接的 URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc 连接的 Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc 连接的 username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc 连接的 password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive 默认在 HDFS 的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>登录MySQL
[lzw@hadoop102 opt]$ mysql -uroot -p
创建 Hive 元数据库
mysql> create database metastore;
初始化 Hive 元数据库
[lzw@hadoop102 hive]$ schematool -initSchema -dbType mysql -verbose
再次启动Hive
[lzw@hadoop102 hive]$ bin/hive
使用元数据服务的方式访问 Hive
在 hive-site.xml 文件中添加如下配置信息
[lzw@hadoop102 hive]$ cd conf/[lzw@hadoop102 conf]$ vim hive-site.xml
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>启动 metastore
[lzw@hadoop102 hive]$ hive --service metastore 2022-07-11 21:19:01: Starting Hive Metastore Server 注意: 启动后窗口不能再操作,需打开一个新的 shell 窗口做别的操作
启动Hive
[lzw@hadoop102 hive]$ hive
使用 JDBC 方式访问 Hive
在 hive-site.xml 文件中添加如下配置信息
<!-- 指定 hiveserver2 连接的 host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 指定 hiveserver2 连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>启动 hiveserver2
得先启动 metastore [lzw@hadoop102 hive]$ hive --service metastore[lzw@hadoop102 hive]$ bin/hive --service hiveserver2 需要多等待一会 直到日志文件出现如下信息(tail -f /tmp/lzw/hive.log) 
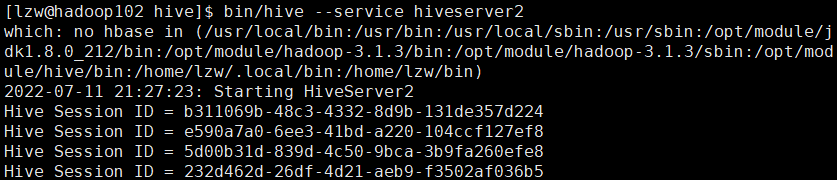
启动 beeline 客户端
[lzw@hadoop102 hive]$ bin/beeline -u jdbc:hive2://hadoop102:10000 -n lzw 这里会失败
修改Hadoop中的 core-site.xml文件
[lzw@hadoop102 hive]$ cd /opt/module/hadoop-3.1.3/etc/hadoop/ 加入以下代码
<property>
<name>hadoop.proxyuser.lzw.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.lzw.groups</name>
<value>*</value>
</property>重启Hadoop集群
[lzw@hadoop102 hadoop]$ myhadoop.sh stop 如果出现下列错误,把hive里的这些终止掉 
[lzw@hadoop102 hadoop]$ myhadoop.sh start
再次启动metastore
[lzw@hadoop102 conf]$ hive --service metastore 2022-07-11 21:46:26: Starting Hive Metastore Serverbin/hive --service hiveserver2 可以使用该命令看看到底启动好没 [lzw@hadoop102 conf]$ sudo netstat -anp|grep 10000
再次启动beeline客户端
[lzw@hadoop102 hive]$ bin/beeline -u jdbc:hive2://hadoop102:10000 -n lzw 看到上图就是启动成功了
看到上图就是启动成功了
编写Hive服务启动脚本
(1)前台启动的方式导致需要打开多个 shell 窗口,可以使用如下方式后台方式启动
nohup: 放在命令开头,表示不挂起,也就是关闭终端进程也继续保持运行状态 /dev/null:是 Linux 文件系统中的一个文件,被称为黑洞,所有写入改文件的内容都会被自动丢弃 2>&1 : 表示将错误重定向到标准输出上 &: 放在命令结尾,表示后台运行 一般会组合使用: nohup [xxx 命令操作]> file 2>&1 &,表示将 xxx 命令运行的结果输出到 file 中,并保持命令启动的进程在后台运行。 [lzw@hadoop202 hive]$ nohup hive --service metastore 2>&1 &[lzw@hadoop202 hive]$ nohup hive --service hiveserver2 2>&1 &
(2)为了方便使用,可以直接编写脚本来管理服务的启动和关闭
[lzw@hadoop102 bin]$ pwd /opt/module/hive/bin[lzw@hadoop102 bin]$ vim hiveservice.sh
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
#检查进程是否运行正常,参数 1 为进程名,参数 2 为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe 服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2 服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore 服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2 服务未启动"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore 服务运行正常" || echo "Metastore 服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2 服务运行正常" || echo "HiveServer2 服务运行异常"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac(3)添加执行权限
[lzw@hadoop102 bin]$ chmod +x hiveservice.sh
(4)启动 Hive 后台服务
[lzw@hadoop102 hive]$ bin/hiveservice.sh start 启动比较慢,需要耐心等一会 [lzw@hadoop102 hive]$ bin/hiveservice.sh status
Hive常用交互命令
如果想用直连方式访问hive
注释掉 /conf/hive-site.xml文件中下列内容 
bin/hive -help
“-e”不进入 hive 的交互窗口执行 sql 语句

“-f”执行脚本中 sql 语句
[lzw@hadoop102 hive]$ vim hive.sql
select * from test;
select count(id) from test;[lzw@hadoop102 hive]$ bin/hive -f hive.sqlhive建表时指定分隔符 指定逗号为分隔符 hive (default)> create table test6(id int, name string) > row format delimited fields terminated by ',';
HBase环境
将jar包传输到linux中
进入到该目录 [lzw@hadoop102 ~]$ cd /opt/software/
解压安装文件到/opt/module下面
[lzw@hadoop102 software]$ tar -zxf hbase-2.4.11-bin.tar.gz -C /opt/module
配置HBase环境变量
[lzw@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh 在文件末尾添加如下内容
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase-2.4.11
export PATH=$PATH:$HBASE_HOME/bin分发一下 [lzw@hadoop102 module]$ xsync /etc/profile.d/my_env.sh 保存后退出,source一下/etc/profile文件(3台),让新的环境变量PATH生效 [lzw@hadoop102 module]$ source /etc/profile.d/my_env.sh
HBase 的配置文件
切换到 conf [lzw@hadoop102 module]$ cd hbase-2.4.11/conf
配置 hbase-env.sh
在文件末尾
export HBASE_MANAGES_ZK=false
配置 hbase-site.xml
修改 configuration 中
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
<description>The directory shared by RegionServers.
</description>
</property>
<!-- <property>-->
<!-- <name>hbase.zookeeper.property.dataDir</name>-->
<!-- <value>/export/zookeeper</value>-->
<!-- <description> 记得修改 ZK 的配置文件 -->
<!-- ZK 的信息不能保存到临时文件夹-->
<!-- </description>-->
<!-- </property>-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop102:8020/hbase</value>
<description>The directory shared by RegionServers.
</description>
</property>配置 regionservers
[lzw@hadoop102 conf]$ vim regionservers
hadoop102
hadoop103
hadoop104解决 HBase 和 Hadoop 的 log4j 兼容性问题
修改 HBase 的 jar 包,使用 Hadoop 的 jar 包 [lzw@hadoop102 conf]$ mv /opt/module/hbase-2.4.11/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar /opt/module/hbase-2.4.11/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar.bak
HBase 远程发送到其他集群
[lzw@hadoop102 module]$ xsync hbase-2.4.11/
HBase 服务的启动
单点启动 [lzw@hadoop102 hbase-2.4.11]$ bin/hbase-daemon.sh start master[lzw@hadoop102 hbase-2.4.11]$ bin/hbase-daemon.sh start regionserver 群起(推荐) [lzw@hadoop102 hbase-2.4.11]$ bin/start-hbase.sh 停止服务 [lzw@hadoop102 hbase-2.4.11]$ bin/stop-hbase.sh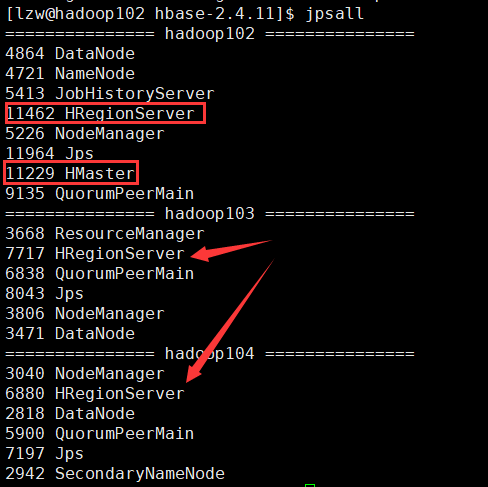
查看 HBase 页面

部署高可用(可选)
关闭 HBase 集群(如果没有开启则跳过此步)
[lzw@hadoop102 hbase-2.4.11]$ bin/stop-hbase.sh
在 conf 目录下创建 backup-masters 文件
[lzw@hadoop102 hbase-2.4.11]$ touch conf/backup-masters
在 backup-masters 文件中配置高可用 HMaster 节点
[lzw@hadoop102 hbase-2.4.11]$ echo hadoop103 > conf/backup-masters
分发
[lzw@hadoop102 hbase-2.4.11]$ xsync conf/backup-masters
重启 hbase,打开页面测试查看
[lzw@hadoop102 hbase-2.4.11]$ bin/start-hbase.sh
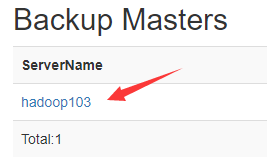
进入HBase Shell
[lzw@hadoop102 ~]$ hbase shell
Spark环境
Local模式
Local 模式,就是不需 要其他任何节点资源就可以在本地执行 Spark 代码的环境,一般用于教学,调试,演示等。
将jar包传输到linux中
进入到该目录 [lzw@hadoop102 ~]$ cd /opt/software/
解压安装文件到/opt/module下面
[lzw@hadoop102 spark-local]$ tar -zxf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module 把目录改个名 [lzw@hadoop102 module]$ mv spark-3.0.0-bin-hadoop3.2/ spark-local
启动 Local 环境
[lzw@hadoop102 spark-standalone]$ bin/spark-shell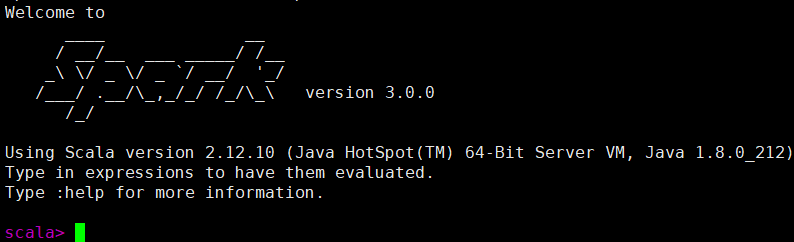 Ctrl+C,
Ctrl+C,:quit退出本地模式
Standalone模式
将jar包传输到linux中
进入到该目录 [lzw@hadoop102 ~]$ cd /opt/software/
解压安装文件到/opt/module下面
[lzw@hadoop102 spark-local]$ tar -zxf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module 把目录改个名 [lzw@hadoop102 module]$ mv spark-3.0.0-bin-hadoop3.2/ spark-standalone
修改配置文件
进入解压缩后路径的 conf 目录,修改 slaves.template 文件名为 slaves [lzw@hadoop102 conf]$ mv slaves.template slaves 修改 slaves 文件,添加 work 节点
hadoop102
hadoop103
hadoop104修改 spark-env.sh.template 文件名为 spark-env.sh [lzw@hadoop102 conf]$ mv spark-env.sh.template spark-env.sh 修改 spark-env.sh 文件,添加 JAVA_HOME 环境变量和集群对应的 master 节点
export JAVA_HOME=/opt/module/jdk1.8.0_212
SPARK_MASTER_HOST=hadoop102
SPARK_MASTER_PORT=7077注意:7077 端口,相当于 hadoop3.x 内部通信的 8020 端口,此处的端口需要确认自己的 Hadoop 配置 分发 spark-standalone 目录 [lzw@hadoop102 module]$ xsync spark-standalone/
启动集群
[lzw@hadoop102 spark-standalone]$ sbin/start-all.sh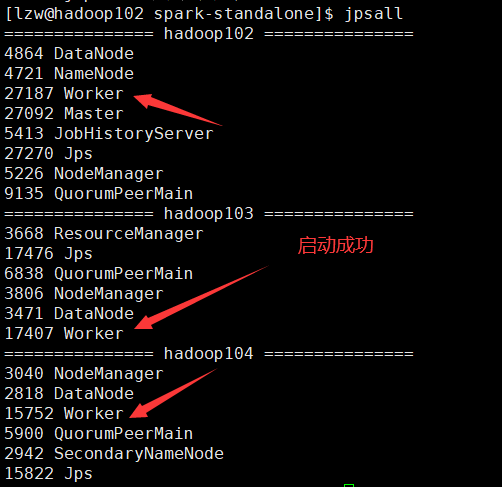 浏览器输入
浏览器输入 [http://hadoop102:8080/](http://hadoop102:8080/) 原因:启动了Zookeeper服务 关闭Zookeeper
原因:启动了Zookeeper服务 关闭Zookeeper [lzw@hadoop102 spark-standalone]$ zk.sh stop 再次浏览器访问(还不行,重启下Spark) 
配置历史服务
修改 spark-defaults.conf.template 文件名为 spark-defaults.conf [lzw@hadoop102 conf]$ mv spark-defaults.conf.template spark-defaults.conf 修改 spark-default.conf 文件,配置日志存储路径
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/directory需要确保 directory目录存在 修改 spark-env.sh 文件, 添加日志配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/directory
-Dspark.history.retainedApplications=30"(参数 1 含义:WEB UI 访问的端口号为 18080 参数 2 含义:指定历史服务器日志存储路径 参数 3 含义:指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。)
分发配置文件 [lzw@hadoop102 spark-standalone]$ xsync conf 重新启动集群和历史服务 [lzw@hadoop102 spark-standalone]$ sbin/start-all.sh[lzw@hadoop102 spark-standalone]$ sbin/start-history-server.sh 执行任务 [lzw@hadoop102 spark-standalone]$ bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop102:7077 ./examples/jars/spark-examples_2.12-3.0.0.jar 10 查看历史服务:http://hadoop102:18080 
配置高可用(HA)
所谓的高可用是因为当前集群中的 Master 节点只有一个,所以会存在单点故障问题。所以为了解决单点故障问题,需要在集群中配置多个 Master 节点,一旦处于活动状态的 Master 发生故障时,由备用 Master 提供服务,保证作业可以继续执行。这里的高可用一般采用 Zookeeper 设置。 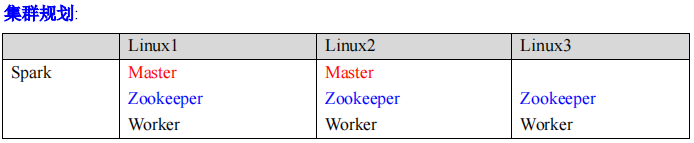 停止集群
停止集群 [lzw@hadoop102 spark-standalone]$ sbin/stop-all.sh 启动Zookeeper [lzw@hadoop102 spark-standalone]$ zk.sh start 修改 spark-env.sh 文件添加如下配置 [lzw@hadoop102 spark-standalone]$ vim conf/spark-env.sh
#注释如下内容:
#SPARK_MASTER_HOST=hadoop102
#SPARK_MASTER_PORT=7077
#Master 监控页面默认访问端口为 8080,但是可能会和 Zookeeper 冲突,所以改成 8989,也可以自定义,访问 UI 监控页面时请注意
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop102,hadoop103,hadoop104
-Dspark.deploy.zookeeper.dir=/spark"分发配置文件 [lzw@hadoop102 spark-standalone]$ xsync conf/ 启动集群 [lzw@hadoop102 spark-standalone]$ sbin/start-all.sh 访问 [http://hadoop102:8989/](http://hadoop102:8989/)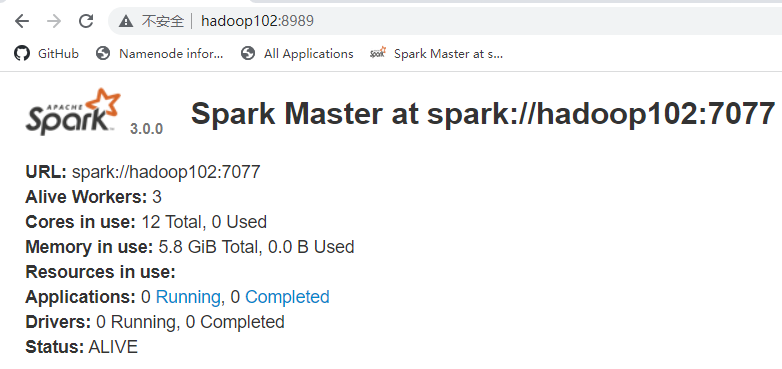 启动 hadoop103 的单独 Master 节点
启动 hadoop103 的单独 Master 节点 [lzw@hadoop103 spark-standalone]$ sbin/start-master.sh 此时 hadoop103 节点 Master 状态处于备用状态  提交应用到高可用集群
提交应用到高可用集群 [lzw@hadoop102 spark-standalone]$ bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop102:7077,hadoop103:7077 ./examples/jars/spark-examples_2.12-3.0.0.jar 10
Yarn模式
独立部署(Standalone)模式由 Spark 自身提供计算资源,无需其他框架提供资源。这 种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住,Spark 主 要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是 和其他专业的资源调度框架集成会更靠谱一些。所以接下来我们来学习在强大的 Yarn 环境下 Spark 是如何工作的(其实是因为在国内工作中,Yarn 使用的非常多)。
将jar包传输到linux中
进入到该目录 [lzw@hadoop102 ~]$ cd /opt/software/
解压安装文件到/opt/module下面
[lzw@hadoop102 spark-local]$ tar -zxf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module 把目录改个名 [lzw@hadoop102 module]$ mv spark-3.0.0-bin-hadoop3.2/ spark-yarn
修改配置文件
修改 hadoop 配置文件 [lzw@hadoop102 module]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其>
杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property><!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其>
杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>修改 conf/spark-env.sh,添加 JAVA_HOME 和 YARN_CONF_DIR 配置 [lzw@hadoop102 conf]$ mv spark-env.sh.template spark-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_212
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop启动 HDFS 以及 YARN 集群
上文中有,不再赘述。
提交应用
[lzw@hadoop102 spark-yarn]$ bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster ./examples/jars/spark-examples_2.12-3.0.0.jar 10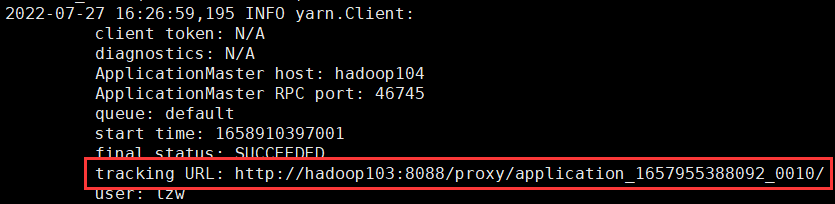 访问 http://hadoop103:8088/cluster
访问 http://hadoop103:8088/cluster
配置历史服务器
修改 spark-defaults.conf.template 文件名为 spark-defaults.conf [lzw@hadoop102 conf]$ mv spark-defaults.conf.template spark-defaults.conf 修改 spark-default.conf 文件,配置日志存储路径
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/directory注意:需要启动 hadoop 集群,HDFS 上的目录需要提前存在。 修改 spark-env.sh 文件, 添加日志配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/directory
-Dspark.history.retainedApplications=30"修改 spark-defaults.conf
spark.yarn.historyServer.address=hadoop102:18080
spark.history.ui.port=18080启动历史服务 [lzw@hadoop102 spark-yarn]$ sbin/start-history-server.sh 重新提交应用 [lzw@hadoop102 spark-yarn]$ bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.12-3.0.0.jar 10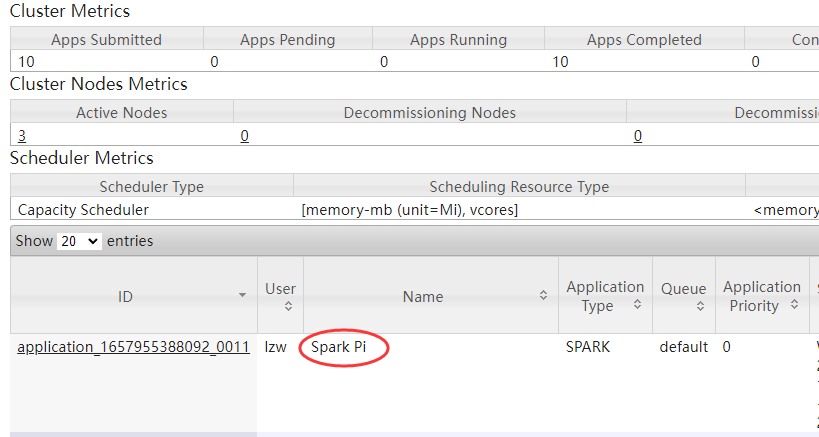
Windows模式
解压缩文件
将文件 spark-3.0.0-bin-hadoop3.2.tgz 解压缩到无中文无空格的路径中
启动本地环境
执行解压缩文件路径下 bin 目录中的 spark-shell.cmd 文件,启动 Spark 本地环境 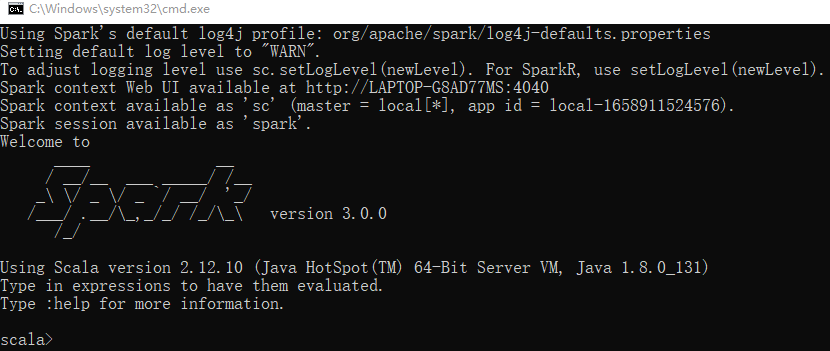 在 bin 目录中创建 input 目录,并添加 word.txt 文件, 在命令行中输入脚本代码
在 bin 目录中创建 input 目录,并添加 word.txt 文件, 在命令行中输入脚本代码 
scala> sc.textFile("input/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
命令行提交应用
在 DOS 命令行窗口中执行提交指令 spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ../examples/jars/spark-examples_2.12-3.0.0.jar 10
部署模式对比

端口号
Spark 查看当前 Spark-shell 运行任务情况端口号:4040(计算) Spark Master 内部通信服务端口号:7077 Standalone 模式下,Spark Master Web 端口号:8080(资源) Spark 历史服务器端口号:18080 Hadoop YARN 任务运行情况查看端口号:8088
网络问题解决
禁用NetworkManager [lzw@hadoop102 hive]$ systemctl stop NetworkManager[lzw@hadoop102 hive]$ systemctl disable NetworkManager[lzw@hadoop102 hive]$ systemctl restart NetworkManager[lzw@hadoop102 hive]$ systemctl restart network 重启虚拟机